Zakres synchronizacji w integracji z hurtownią decyduje o stabilności całego katalogu. Sprawdź, które dane warto automatyzować od razu, czego nie kopiować bez reguł i jak zaplanować wdrożenie etapami, żeby ograniczyć błędy oraz chaos w ofercie.
Najbezpieczniej zacząć od synchronizacji danych krytycznych: cen, stanów, dostępności, SKU i EAN. Dopiero potem warto dodawać opisy, zdjęcia, atrybuty i reguły biznesowe. Kluczowe są mapowanie pól, walidacja oraz wdrożenie etapami, bo to one ograniczają błędy i utrzymują porządek w katalogu.
Najważniejsze wnioski
- Zakres synchronizacji ma większe znaczenie niż sam mechanizm integracji.
- Na start synchronizuj dane krytyczne: ceny, stany, dostępność i identyfikatory produktów.
- Opisy, zdjęcia i kategorie wymagają osobnych reguł i kontroli jakości.
- Mapowanie pól i walidacja danych są podstawą stabilnej integracji.
- Najlepsze efekty daje wdrożenie etapowe zamiast pełnego importu od razu.
- Integrację warto rozwijać wraz ze wzrostem katalogu i procesów sprzedażowych.
- Dlaczego zakres synchronizacji jest ważniejszy niż sam typ integracji
- Jakie dane synchronizować w pierwszej kolejności
- Czego nie kopiować bez dodatkowych reguł
- Jak ustalić źródło prawdy dla cen i stanów
- Mapowanie pól i walidacja danych
- Synchronizacja etapami zamiast pełnego importu na start
- Jak ograniczać błędy po wdrożeniu
- Kiedy rozszerzyć zakres synchronizacji
- Jak projektujemy takie wdrożenia
Dlaczego zakres synchronizacji jest ważniejszy niż sam typ integracji
W integracjach z hurtownią najwięcej problemów nie wynika z samej technologii, ale z tego, jakie dane mają przepływać między systemami i w jaki sposób będą aktualizowane. API, XML, CSV czy inny mechanizm to tylko narzędzie. O stabilności wdrożenia decyduje przede wszystkim zakres synchronizacji, reguły aktualizacji i sposób kontroli danych.
Jeżeli od początku ustalisz, które dane są krytyczne, a które mogą być aktualizowane później, łatwiej utrzymasz porządek w ofercie i ograniczysz ręczne poprawki. To szczególnie ważne w projektach e-commerce, stronach produktowych oraz przy rozbudowanych katalogach, gdzie jedna błędna synchronizacja potrafi wprowadzić chaos do całej struktury.
- zakres synchronizacji powinien wynikać z procesu sprzedaży
- nie wszystkie dane muszą być aktualizowane w czasie rzeczywistym
- integracja ma wspierać porządek, a nie go zaburzać
Jakie dane synchronizować w pierwszej kolejności
Najlepszym punktem startowym są dane krytyczne dla działania oferty. W praktyce chodzi przede wszystkim o ceny, stany magazynowe, dostępność, SKU, EAN oraz podstawowe identyfikatory produktów. To one decydują o tym, czy klient widzi aktualną ofertę i czy zamówienie da się obsłużyć bez ręcznych korekt.
Drugą warstwę tworzą dane pomocnicze: warianty, podstawowe parametry techniczne, jednostki miary, kody producenta i przypisania do kategorii. Tę grupę również można synchronizować, ale dopiero wtedy, gdy struktura po obu stronach jest dobrze uporządkowana. W praktyce daje to najlepszy efekt: najpierw stabilność, potem pełniejsze wzbogacanie katalogu.
- ceny i waluty
- stany magazynowe i dostępność
- SKU, EAN i identyfikatory
- warianty i podstawowe atrybuty
- kategorie i przypisania produktowe
Czego nie kopiować bez dodatkowych reguł
Nie każdy element oferty powinien trafiać do strony automatycznie. Najwięcej pracy porządkowej zwykle generują opisy, zdjęcia, nazwy marketingowe i struktura kategorii. Jeśli hurtownia dostarcza surowe dane techniczne, strona potrzebuje warstwy selekcji i dopracowania, żeby katalog był czytelny, spójny i przydatny dla użytkownika.
Zdjęcia są dobrym przykładem. Automatyczne pobieranie plików może przyspieszyć pracę, ale bez walidacji łatwo o duplikaty, błędne miniatury albo różnice w jakości materiałów. Podobnie z kategoriami: struktura hurtowni zwykle nie odpowiada 1:1 architekturze sprzedażowej strony. Zamiast kopiować ją bez zmian, lepiej mapować tylko te elementy, które wspierają nawigację i SEO.
- długie opisy bez kontroli jakości
- zdjęcia bez walidacji i ograniczeń
- kategorie kopiowane 1:1
- atrybuty niestandardowe, które mogą się dublować
Jak ustalić źródło prawdy dla cen i stanów
Jedna z najważniejszych decyzji dotyczy tego, kto zarządza danymi nadrzędnymi. W przypadku cen i stanów zazwyczaj źródłem prawdy jest hurtownia, ale sklep może mieć własne reguły marżowe, promocje i statusy dostępności. To nie musi się wykluczać, jeśli zasady zostaną dobrze opisane.
Najlepiej rozdzielić dane globalne od lokalnych. Hurtownia dostarcza cenę bazową i stan, a strona nakłada własną logikę biznesową: marżę, próg promocyjny, oznaczenie „na zamówienie” albo blokadę widoczności przy niskiej dostępności. Dzięki temu integracja jest elastyczna i mniej podatna na nieporozumienia.
- ustal cenę bazową po stronie źródła
- zdefiniuj zasady marży i promocji
- określ logikę statusów dostępności
- przygotuj wyjątki dla produktów specjalnych
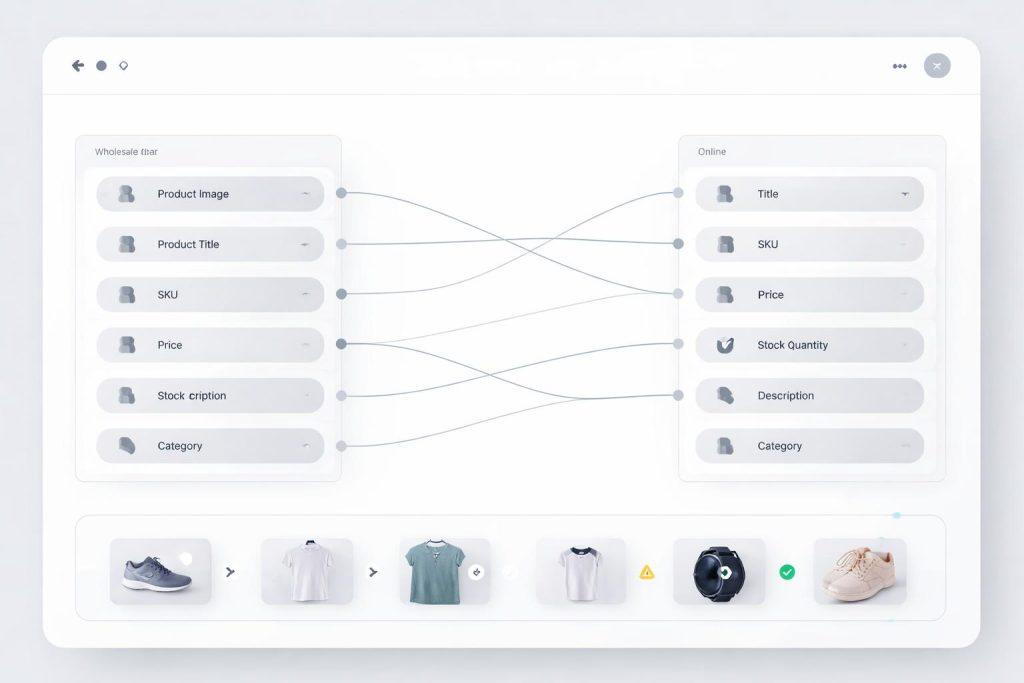
Mapowanie pól i walidacja danych
Mapowanie pól to techniczny etap, w którym konkretne dane z hurtowni przypisuje się do odpowiednich pól na stronie. Dzięki temu wiadomo, że cena trafia do ceny produktu, a identyfikator produktu pozostaje tam, gdzie system może go później rozpoznać. To właśnie na tym etapie najczęściej zapada decyzja, jak przełożyć feed na strukturę katalogu.
Równie ważna jest walidacja. Nie chodzi o rozbudowane bariery, ale o proste reguły porządkujące: rekord musi mieć wymagane pola, dane muszą być zgodne z formatem, a błędne lub niepełne pozycje nie powinny nadpisywać poprawnej oferty. Dobrze ustawione mapowanie i walidacja sprawiają, że integrację łatwiej rozwijać, a nowe grupy produktów można dodawać bez przebudowy całej logiki.
- nazwy produktów i SKU
- ceny i waluty
- stany i statusy dostępności
- atrybuty techniczne
- linki do zdjęć i plików
Synchronizacja etapami zamiast pełnego importu na start
Najczęstszy błąd polega na uruchomieniu pełnej synchronizacji od razu. Znacznie lepiej działa wdrożenie etapowe: najpierw dane krytyczne, potem atrybuty, następnie opisy, a na końcu elementy dodatkowe, jeśli rzeczywiście są potrzebne. Taki model pozwala szybciej wykryć błędy i nie przeciąża sklepu wieloma zmianami naraz.
Etapowe wdrożenie ułatwia też pracę zespołowi obsługującemu ofertę. Zamiast analizować setki zmian po jednym dużym imporcie, można sprawdzać konkretne obszary i od razu poprawiać to, co wymaga korekty. W projektach, które prowadzimy, właśnie taki model zwykle daje najlepszą przewidywalność i najmniej poprawek po starcie.
- start od danych krytycznych
- test na ograniczonej grupie produktów
- weryfikacja importu przed pełnym uruchomieniem
- rozszerzanie zakresu dopiero po kontroli wyników
Jak ograniczać błędy po wdrożeniu
Po uruchomieniu integracji warto monitorować nie tylko sam import, ale też jego skutki w katalogu. Trzeba obserwować, czy dane aktualizują się zgodnie z harmonogramem, czy nie pojawiają się duplikaty i czy struktura feedu nie zmieniła się po stronie źródła. Dobrze działa też jasny podział odpowiedzialności: część danych aktualizuje się automatycznie, część pozostaje pod kontrolą redakcyjną, a część jest zmieniana tylko w określonych przypadkach.
W naszych wdrożeniach integracje API i rozwiązania dedykowane projektujemy tak, żeby zakres synchronizacji był dopasowany do danych, a nie odwrotnie. Jeśli chcesz uporządkować obecny proces albo zaplanować nowe wdrożenie, możesz od razu przejść do [kontaktu](https://mcwebdesign.pl/) i opisać, jak działa dziś Twoja strona lub sklep.
- monitoruj błędy importu i odrzucone rekordy
- sprawdzaj zmiany struktury feedu
- ustal procedurę aktualizacji mapowania
- kontroluj jakość zdjęć, opisów i wariantów

Kiedy rozszerzyć zakres synchronizacji
Zakres synchronizacji nie musi być stały. Najlepiej traktować go jako element, który dojrzewa razem ze stroną i ofertą. Gdy podstawowy import działa stabilnie, można dodawać kolejne warstwy: nowe atrybuty, warianty, opisy, multimedia lub reguły cenowe. To naturalny etap rozwoju, szczególnie wtedy, gdy katalog rośnie i ręczna obsługa przestaje być efektywna.
Rozszerzanie integracji ma sens wtedy, gdy każdy nowy element ma jasne uzasadnienie biznesowe. W praktyce lepiej dołożyć jedną dobrze opisaną funkcję niż kilka przypadkowych rozszerzeń, które później utrudniają utrzymanie. Właśnie dlatego przy projektach stron internetowych i sklepów internetowych plan integracji warto łączyć z architekturą danych już na początku.
- gdy podstawowa synchronizacja działa stabilnie
- gdy katalog rośnie i wymaga automatyzacji
- gdy ręczne poprawki zajmują zbyt dużo czasu
- gdy pojawiają się nowe typy danych do obsługi
Jak projektujemy takie wdrożenia
W praktyce najlepiej działają rozwiązania, które łączą analizę danych, projekt techniczny i dopasowanie do realnego procesu sprzedaży. Dlatego przy integracjach z hurtowniami ważne jest nie tylko to, co da się przesłać, ale też to, jak strona ma później z tych danych korzystać. Taki sposób pracy pozwala budować katalogi, które są czytelne dla użytkowników i wygodne w utrzymaniu.
Przy projektach e-commerce, stronach ofertowych i systemach dedykowanych dbamy o to, żeby logika synchronizacji była skalowalna i możliwa do rozwoju. To samo dotyczy realizacji lokalnych, takich jak [strony internetowe Mielec](https://mcwebdesign.pl/) czy [sklepy internetowe Mielec](https://mcwebdesign.pl/), gdzie liczy się zarówno porządek w danych, jak i wygoda dalszej rozbudowy. Jeśli budujesz nową stronę albo porządkujesz istniejący katalog, integrację z hurtownią warto zaplanować razem z całą architekturą projektu.
- analiza źródeł danych
- mapowanie pól i reguł biznesowych
- wdrożenie etapowe
- testy na realnych produktach
- monitoring po starcie
Checklist
- Ustal, które dane mają aktualizować się automatycznie, a które pozostają pod kontrolą redakcyjną.
- Określ źródło prawdy dla cen, stanów, nazw i identyfikatorów produktów.
- Przygotuj mapowanie pól między hurtownią a stroną przed pierwszym importem.
- Oddziel dane krytyczne od marketingowych i ustaw dla nich różną częstotliwość synchronizacji.
- Zdefiniuj zasady walidacji rekordów: co importujemy, a co odrzucamy.
- Przetestuj integrację na ograniczonej grupie produktów przed pełnym uruchomieniem.
- Ustal procedurę kontroli po wdrożeniu: monitoring błędów, duplikatów i zmian struktury feedu.
- Rozszerzaj zakres synchronizacji dopiero wtedy, gdy podstawowy proces działa stabilnie.
FAQ
Jakie dane warto synchronizować z hurtownią w pierwszej kolejności?
Na początek najlepiej synchronizować dane krytyczne dla sprzedaży: ceny, stany magazynowe, dostępność, SKU, EAN i identyfikatory produktów. To zapewnia aktualność oferty i porządek w katalogu.
Czy opisy i zdjęcia powinny być synchronizowane automatycznie?
Tak, ale zwykle dopiero po wdrożeniu podstawowej synchronizacji i ustaleniu reguł jakości. Opisy marketingowe, zdjęcia i część atrybutów warto wprowadzać etapami, aby zachować spójność treści i uniknąć duplikatów.
Kto powinien być źródłem prawdy dla cen i stanów magazynowych?
Najczęściej źródłem prawdy jest hurtownia, natomiast sklep może nakładać własne reguły biznesowe, takie jak marża, promocje czy statusy dostępności. Ważne jest jasne ustalenie tej logiki przed wdrożeniem.
Dlaczego mapowanie pól jest tak ważne w integracji z hurtownią?
Mapowanie pól decyduje o tym, czy dane trafiają we właściwe miejsca w systemie. Dzięki temu cena trafia do ceny produktu, SKU do identyfikatora, a atrybuty techniczne do odpowiednich pól, co ogranicza błędy i ułatwia rozwój integracji.
Kiedy warto rozszerzyć zakres synchronizacji?
Gdy podstawowa synchronizacja działa stabilnie, katalog rośnie albo ręczna obsługa zajmuje zbyt dużo czasu. Wtedy można bezpiecznie dodać kolejne warstwy danych, takie jak opisy, multimedia, nowe atrybuty czy reguły cenowe.
Podsumowanie
Dobrze zaplanowana integracja strony z hurtownią nie polega na tym, żeby przesłać jak najwięcej danych, ale na tym, żeby ustawić właściwy zakres synchronizacji. Najpierw warto objąć automatyzacją elementy krytyczne: ceny, stany, dostępność i identyfikatory. Dopiero później opłaca się rozwijać opisy, zdjęcia, atrybuty i reguły biznesowe. Kluczem są mapowanie pól, walidacja i wdrożenie etapowe, bo to one pozwalają utrzymać porządek w katalogu oraz ograniczyć błędy po stronie sklepu.


