Praktyczny przewodnik po przygotowaniu specyfikacji integracji API dla konfiguratora produktu. Zobacz, jak opisać wymagania, endpointy, payloady, walidację, scenariusze użycia i kryteria odbioru, żeby wdrożenie było przewidywalne i bezpieczne.
Specyfikacja integracji API dla konfiguratora produktu powinna opisywać cel biznesowy, źródła danych, odpowiedzialność systemów, endpointy, payloady, reguły walidacji, błędy, scenariusze użycia oraz kryteria odbioru. Najlepiej budować ją od procesu użytkownika i logiki biznesowej, a nie od samej listy metod API.
Najważniejsze wnioski
- Zacznij od celu biznesowego konfiguratora, a nie od endpointów.
- Jasno określ system źródłowy dla każdego typu danych.
- Opisuj endpointy według kroków użytkownika i logiki sprzedaży.
- Rozdziel dane wejściowe, wyliczane i pobierane z systemów zewnętrznych.
- Walidacja musi obejmować format danych i reguły kompatybilności.
- Scenariusze błędne i fallbacki są równie ważne jak ścieżki pozytywne.
- Dodaj kryteria akceptacji, testy i zasady odbioru integracji.
- Uwzględnij wersjonowanie, cache, retry i częściową niedostępność danych.
- Dlaczego specyfikacja API jest kluczowa przy konfiguratorze produktu
- Jak zebrać wymagania przed opisaniem endpointów
- Jak opisać architekturę integracji i odpowiedzialność systemów
- Jak zdefiniować endpointy dla konfiguratora produktu
- Jak projektować payloady, żeby nie było niejasności
- Jak opisać walidację, reguły biznesowe i scenariusze błędne
- Jak zaplanować scenariusze użycia od wyboru do zamówienia
- Jak przygotować dokumentację, testy i odbiór integracji
- Najczęstsze błędy przy specyfikacji API dla konfiguratora produktu
- Jak wykorzystać specyfikację w dalszym rozwoju konfiguratora
Dlaczego specyfikacja API jest kluczowa przy konfiguratorze produktu
Konfigurator produktu zazwyczaj nie działa w izolacji. Pobiera dane z katalogu, ERP, systemu cenowego, magazynu, CMS, a czasem także z usług zewnętrznych. Odpowiada za warianty, reguły kompatybilności, wycenę, dostępność i przekazanie gotowej konfiguracji do koszyka lub procesu sprzedażowego.
Jeżeli specyfikacja API jest niepełna, zespoły zaczynają dopowiadać założenia po swojej stronie. Frontend pokazuje coś, czego backend nie akceptuje. ERP zwraca inne ceny niż sklep. UX projektuje flow, którego nie da się obsłużyć technicznie. W efekcie integracja staje się serią poprawek zamiast kontrolowanego wdrożenia.
Dobra specyfikacja porządkuje odpowiedzialności, upraszcza testy i skraca czas decyzji. Ułatwia też rozwój konfiguratora w przyszłości, bo kolejne funkcje można dopinać do spójnego modelu danych i procesu.
- Ustala wspólny język dla biznesu, UX, frontendu i backendu.
- Określa źródło prawdy dla każdego typu danych.
- Pomaga przewidzieć błędy, limity i scenariusze brzegowe.
Jak zebrać wymagania przed opisaniem endpointów
Najpierw trzeba ustalić, co konfigurator ma realnie robić z perspektywy biznesu. Inaczej opisuje się prosty wybór koloru i rozmiaru, a inaczej złożoną konfigurację z zależnościami, dodatkami, limitami technologicznymi i automatyczną wyceną. Endpointy powinny wynikać z procesu, a nie odwrotnie.
Na tym etapie warto zebrać wszystkie źródła danych: katalog produktów, cenniki, stany magazynowe, reguły kompatybilności, ograniczenia produkcyjne, treści marketingowe oraz dane o dostępności wariantów. Każde pole powinno mieć właściciela i jasno opisane źródło.
Dobrym podejściem jest podział wymagań na trzy obszary: biznesowy, techniczny i użytkowy. Biznes definiuje cel i zasady. Technika wskazuje systemy, integracje i ograniczenia. UX opisuje sposób przechodzenia przez kolejne kroki konfiguracji oraz momenty, w których użytkownik potrzebuje informacji zwrotnej.
- Cel biznesowy konfiguratora i miernik sukcesu.
- Zakres opcji, wariantów i reguł zależności.
- Systemy źródłowe i częstotliwość synchronizacji.
- Wydajność, cache, timeouty i retry.
- Scenariusze użytkownika i punkty decyzji.
Jak opisać architekturę integracji i odpowiedzialność systemów
W specyfikacji trzeba wyraźnie wskazać, który system jest źródłem prawdy dla danego rodzaju danych. Katalog może dostarczać warianty i opisy. ERP może dostarczać ceny i stany. Konfigurator zwykle agreguje, waliduje i prezentuje wynik, ale nie powinien sam wymyślać logiki, która należy do systemu nadrzędnego.
Warto też opisać przepływ danych: skąd trafiają do API, kiedy są cache’owane, co dzieje się po zmianie wyboru i gdzie zapisuje się finalna konfiguracja. Jeśli architektura jest synchroniczna, asynchroniczna albo hybrydowa, musi to być jasno opisane, bo wpływa na obsługę opóźnień, błędów i spójność danych.
W projektach headless commerce ważne jest uwzględnienie frontendu, sklepu, CMS, middleware i ewentualnych usług pośrednich. Jedna, wspólna mapa odpowiedzialności ogranicza liczbę nieporozumień między zespołami i ułatwia późniejsze utrzymanie systemu.
- System źródłowy i system docelowy dla każdego typu danych.
- Model komunikacji: synchroniczny, asynchroniczny lub mieszany.
- Miejsca cache’owania, odświeżania i invalidacji danych.
- Rola frontendu, backendu, koszyka i systemów zewnętrznych.
- Zasady odpowiedzialności za logikę biznesową.
Jak zdefiniować endpointy dla konfiguratora produktu
Endpointy powinny być projektowane pod konkretne kroki użytkownika. Najczęściej potrzebne są zasoby do pobrania danych startowych, list wariantów, zależności między opcjami, wyceny, walidacji i zapisania finalnej konfiguracji. W bardziej rozbudowanych przypadkach dochodzą treści wspierające, obrazy, modele 3D, dostępność magazynowa i dane zależne od rynku.
Każdy endpoint powinien mieć identyczny schemat opisu: metoda HTTP, ścieżka, cel, parametry wejściowe, przykładowy response, błędy, zależności i uwagi dotyczące cache. Dzięki temu frontend wie, kiedy odpytać API, czego oczekiwać w odpowiedzi i jak zareagować na błąd.
Lepiej przygotować mniej endpointów, ale dobrze opisanych, niż dziesiątki małych punktów integracji bez jasnego przeznaczenia. Jeżeli jeden endpoint może zwrócić komplet danych potrzebnych na danym etapie, zwykle warto rozważyć takie podejście.
- Endpoint startowy z danymi produktu i wariantów.
- Endpoint do kalkulacji ceny i dopłat.
- Endpoint do sprawdzania kompatybilności opcji.
- Endpoint do walidacji przed dodaniem do koszyka.
- Endpoint do zapisu szkicu lub finalnego zestawu.
Jak projektować payloady, żeby nie było niejasności
Payload to miejsce, w którym najczęściej pojawiają się rozbieżności interpretacyjne. Dlatego trzeba jasno opisać strukturę danych, typy pól, pola wymagane i opcjonalne oraz to, które wartości są wejściowe, wyliczane albo pobierane z systemów zewnętrznych.
W konfiguratorze szczególnie ważne są identyfikatory produktu, wariantu i opcji, ilości, parametry techniczne, kody atrybutów oraz wartości zależne od reguł. Nie wystarczy napisać, że „należy przekazać dane produktu”. Trzeba pokazać, co dokładnie oznacza dany obiekt i kto ma prawo go nadpisać.
Warto też od razu przewidzieć wersjonowanie schematu. Konfigurator rozwija się w czasie, a payload musi pozwolić na dodawanie nowych pól bez łamania istniejących integracji. To szczególnie ważne, gdy proces obejmuje sklep, ERP, CRM i system obsługi zamówień.
- Pola wymagane, opcjonalne i wyliczane.
- Identyfikatory produktu, wariantu i opcji.
- Źródło wartości: użytkownik, API, kalkulator, system zewnętrzny.
- Wersjonowanie struktury i zgodność wsteczna.
- Przykłady dla kilku realnych kombinacji konfiguracji.
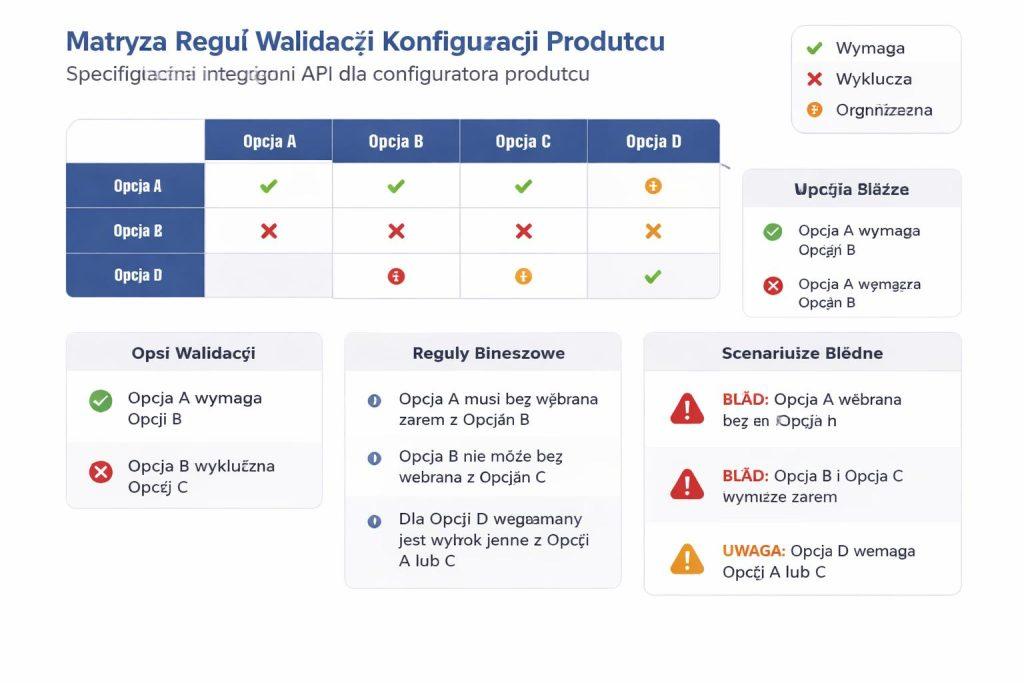
Jak opisać walidację, reguły biznesowe i scenariusze błędne
Walidacja w konfiguratorze nie kończy się na poprawności formatu. Trzeba jeszcze sprawdzić, czy dana kombinacja ma sens biznesowy. Dlatego specyfikacja powinna rozdzielać walidację składniową od walidacji regułowej. Pierwsza sprawdza typy danych, obecność pól i format. Druga odpowiada za kompatybilność opcji, dostępność, limity i zależności między wariantami.
Reguły najlepiej zapisywać w konkretnej formie. Jeśli wybrano opcję A, opcja B jest niedostępna. Jeśli materiał ma określoną grubość, nie można przekroczyć danego wymiaru. Jeśli stan magazynowy jest zerowy, system proponuje alternatywę albo blokuje finalizację. Takie zapisy są znacznie bardziej użyteczne niż ogólnikowe zdanie o konieczności walidacji.
Scenariusze błędne są równie ważne jak poprawne. Trzeba opisać, co dzieje się, gdy API nie odpowiada, brakuje ceny, nie da się policzyć kombinacji albo użytkownik wybiera niekompatybilny wariant. Dzięki temu system zachowuje się przewidywalnie także w sytuacjach awaryjnych.
- Walidacja formatu danych i wymaganych pól.
- Walidacja zależności między opcjami.
- Obsługa brakujących cen, stanów i reguł.
- Komunikaty błędów zrozumiałe dla użytkownika i zespołu.
- Fallbacki przy częściowej niedostępności danych.
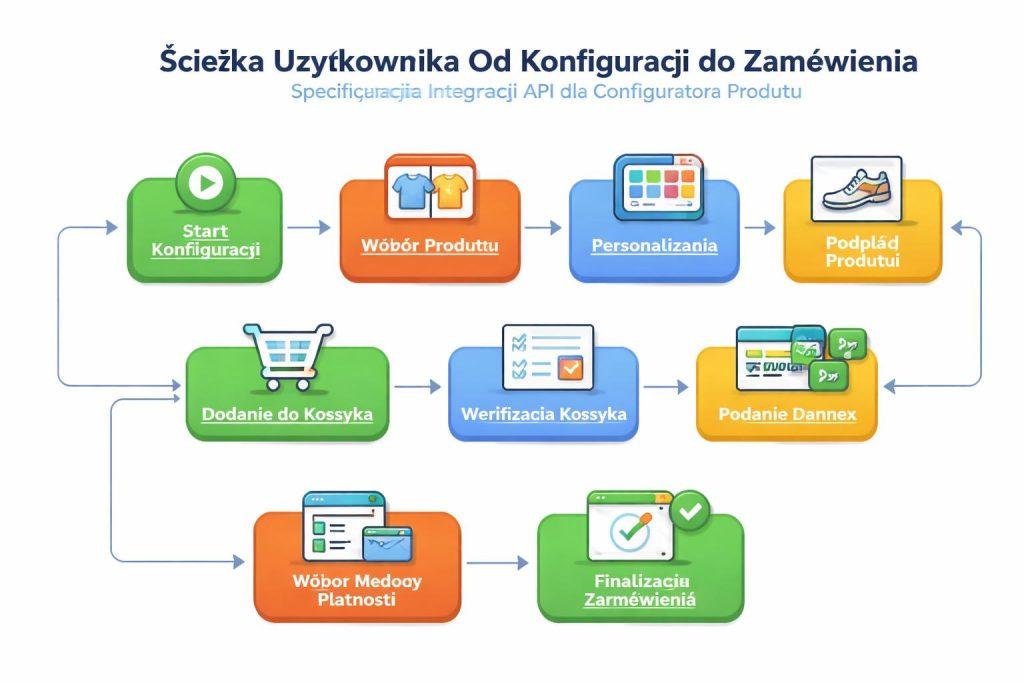
Jak zaplanować scenariusze użycia od wyboru do zamówienia
Sama lista endpointów nie wystarczy. Specyfikacja powinna opisywać rzeczywisty przebieg użytkownika: wejście na kartę produktu, wybór wariantu bazowego, dynamiczną aktualizację ceny, dołożenie akcesoriów, walidację dostępności, zapis konfiguracji i przekazanie jej do koszyka lub oferty PDF. Tylko wtedy widać, czy API wspiera sprzedaż, a nie jedynie strukturę danych.
Warto opisać również scenariusze alternatywne. Co się dzieje, gdy użytkownik wraca do poprzedniego kroku? Jak system zachowuje się po zmianie opcji, która unieważnia wcześniejsze wybory? Co z zapisanym szkicem konfiguracji po zalogowaniu? Takie przypadki często decydują o jakości całego rozwiązania.
Scenariusze najlepiej pisać językiem procesu biznesowego, a dopiero potem mapować je na konkretne endpointy. To ułatwia rozmowę z klientem, sprzedażą, obsługą zamówień i QA.
- Start konfiguracji i pobranie danych wejściowych.
- Zmiana opcji i odświeżenie zależnych wartości.
- Weryfikacja przed dodaniem do koszyka.
- Zapis szkicu, powrót i odtworzenie stanu.
- Finalizacja i przekazanie danych do kolejnego systemu.
Jak przygotować dokumentację, testy i odbiór integracji
Dobrze napisana specyfikacja musi być testowalna. Dlatego w dokumencie powinny znaleźć się kryteria akceptacji, przykładowe requesty i response’y oraz przypadki testowe. Zespół QA powinien na ich podstawie przygotować scenariusze bez dodatkowych doprecyzowań.
Warto też opisać środowiska i zasady pracy na nich: test, staging i produkcja, autoryzacja, limity, klucze API, ustawienia CORS oraz sposób wersjonowania. Jeśli integracja obejmuje wiele systemów, przydaje się informacja, które dane są mockowane, a które pobierane z realnego źródła.
Odbiór integracji powinien opierać się na konkretach: czy wszystkie scenariusze działają, czy błędy są zgodne ze specyfikacją, czy dane trafiają do właściwych systemów i czy są zgodne z oczekiwanym formatem. Bez tego wdrożenie bywa formalnie zamknięte, ale praktycznie niegotowe.
- Kryteria akceptacji dla każdego endpointu.
- Przykładowe requesty i response’y.
- Przypadki testowe pozytywne i negatywne.
- Zasady dostępu do środowisk i autoryzacji.
- Warunki odbioru i odpowiedzialność po wdrożeniu.
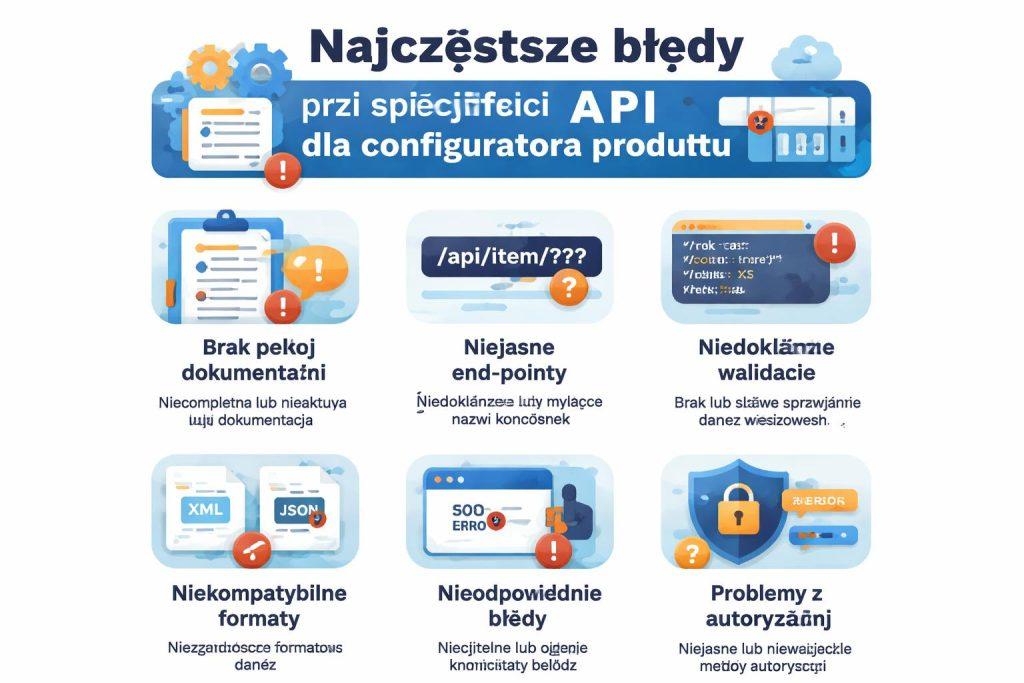
Najczęstsze błędy przy specyfikacji API dla konfiguratora produktu
Najczęstszy błąd to zaczynanie od endpointów zamiast od procesu i odpowiedzialności systemów. Wtedy specyfikacja opisuje technikę, ale nie wspiera realnej sprzedaży. Kolejny problem to brak rozdziału na dane wejściowe, wyliczane i pochodzące z innych systemów.
Bardzo często pomija się scenariusze błędne, fallbacki i wersjonowanie. Na etapie wdrożenia okazuje się wtedy, że nie wiadomo, co zrobić z chwilowym brakiem ceny, zerowym stanem magazynowym albo niekompatybilną opcją. To zwiększa ryzyko poprawek i opóźnień.
Błędem jest także zbyt ogólny opis payloadów i brak przykładów. Jeśli dokument nie pokazuje realnych kombinacji danych, zespół będzie interpretował go na różne sposoby. A to prawie zawsze kończy się dodatkowymi iteracjami.
- Projektowanie od endpointów zamiast od procesu.
- Brak źródła prawdy dla danych.
- Nieprecyzyjne payloady i brak przykładów.
- Pomijanie błędów, fallbacków i wersjonowania.
- Brak kryteriów akceptacji i scenariuszy testowych.
Jak wykorzystać specyfikację w dalszym rozwoju konfiguratora
Dobra specyfikacja nie kończy życia projektu, tylko otwiera drogę do jego rozwoju. Gdy dokument jest spójny, łatwiej dołożyć nowe warianty, kolejne kanały sprzedaży, integrację z marketplace albo synchronizację z innym systemem produkcyjnym.
W praktyce taki dokument staje się punktem odniesienia dla rozbudowy konfiguratora o nowe kroki, reguły i źródła danych. Ułatwia też onboarding nowych osób w zespole, bo tłumaczy nie tylko co system robi, ale dlaczego działa właśnie w ten sposób.
Warto traktować specyfikację jak żywy dokument. Po wdrożeniu powinna być aktualizowana razem ze zmianami w API, w regułach biznesowych i w procesie sprzedażowym. Dzięki temu nie zamienia się w archiwum, tylko realne narzędzie utrzymania.
- Ułatwia rozbudowę o nowe warianty i kanały sprzedaży.
- Wspiera onboarding nowych członków zespołu.
- Pomaga utrzymać spójność między biznesem a technologią.
- Skraca czas analizy przy kolejnych integracjach.
- Zmniejsza ryzyko długu technicznego w rozwoju konfiguratora.
Checklist
- Ustal cel biznesowy konfiguratora i miernik sukcesu.
- Zidentyfikuj wszystkie systemy źródłowe danych.
- Opisz odpowiedzialność każdego systemu.
- Zdefiniuj przebieg użytkownika krok po kroku.
- Wypisz wymagane endpointy i ich przeznaczenie.
- Określ strukturę payloadów, typy pól i wersjonowanie.
- Dodaj walidację, reguły biznesowe i komunikaty błędów.
- Opisz scenariusze pozytywne, negatywne i brzegowe.
- Zdefiniuj zasady cache, retry, timeoutów i fallbacków.
- Przygotuj przykłady requestów i response’ów.
- Dodaj kryteria akceptacji i przypadki testowe.
- Ustal zasady odbioru i odpowiedzialność za utrzymanie integracji.
FAQ
Czym różni się specyfikacja API konfiguratora od zwykłej dokumentacji endpointów?
Specyfikacja konfiguratora opisuje nie tylko endpointy, ale też proces biznesowy, odpowiedzialność systemów, reguły walidacji, zależności między opcjami, scenariusze błędne i kryteria odbioru. Dzięki temu dokument nadaje się do wdrożenia, testów i dalszego rozwoju.
Jakie endpointy najczęściej są potrzebne w konfiguratorze produktu?
Najczęściej są to endpointy do pobierania danych startowych, list wariantów, reguł kompatybilności, kalkulacji ceny, walidacji konfiguracji, zapisania szkicu oraz finalnego przekazania konfiguracji do koszyka lub innego systemu.
Kto powinien przygotować specyfikację integracji API?
Najlepiej przygotowuje ją zespół łączący kompetencje biznesowe, analityczne i techniczne: lider projektu, analityk, backend developer, frontend developer, UX i osoba odpowiedzialna za integracje. W praktyce dokument powstaje wspólnie, a nie w jednym dziale.
Czy konfigurator powinien sam liczyć cenę, czy pobierać ją z API?
To zależy od architektury, ale w specyfikacji trzeba jasno wskazać system źródłowy. Jeśli cena zależy od ERP, cennika lub reguł handlowych, lepiej, aby API zwracało wartość obliczoną lub potwierdzoną przez system nadrzędny. Frontend nie powinien zgadywać ceny.
Jakie błędy najczęściej psują integrację konfiguratora z API?
Najczęstsze problemy to brak rozdzielenia odpowiedzialności między systemami, niepełne payloady, brak reguł walidacji, zbyt ogólne opisy błędów, brak scenariuszy alternatywnych, brak wersjonowania oraz pominięcie testów akceptacyjnych.
Podsumowanie
Dobrze przygotowana specyfikacja integracji API dla konfiguratora produktu porządkuje wymagania, skraca wdrożenie i zmniejsza ryzyko błędów. Powinna łączyć biznes, UX i technologię w jeden spójny dokument: od celu i źródeł danych, przez endpointy i payloady, po walidację, scenariusze użycia, testy i odbiór. To fundament stabilnego konfiguratora, który da się rozwijać bez chaosu.


