Praktyczny przewodnik po wdrożeniu konfiguratora produktów zasilanego danymi z ERP, PIM, magazynu lub systemu producenta przez API. Dowiedz się, jak zaprojektować architekturę, model danych, synchronizację, panel administracyjny i zabezpieczenia, aby oferta aktualizowała się automatycznie bez ręcznej edycji.
Konfigurator produktów z API najlepiej wdrożyć przez warstwę integracyjną, która pobiera dane z ERP, PIM, magazynu lub systemu producenta, normalizuje je do jednego modelu i udostępnia konfiguratorowi aktualne ceny, stany, warianty oraz reguły bez ręcznej edycji oferty.
Najważniejsze wnioski
- Najpierw projektuje się model danych i źródła prawdy, a dopiero potem frontend konfiguratora.
- Warstwa integracyjna powinna oddzielać konfigurator od bezpośrednich połączeń z wieloma API.
- Najlepiej sprawdza się model hybrydowy: cache, webhooki i okresowa synchronizacja.
- Panel administracyjny jest kluczowy do monitorowania synchronizacji, błędów i wyjątków.
- Reguły kompatybilności, walidacja i wersjonowanie danych są tak samo ważne jak ceny i opisy.
- Integracje muszą uwzględniać timeouty, retry, limity, logowanie i fallbacki.
- Dobrze wdrożony konfigurator ogranicza błędy ofertowe i odciąża sprzedaż oraz administrację.
- Dlaczego konfigurator produktów powinien korzystać z API
- Jakie dane powinny przepływać między systemami a konfiguratoriem
- Architektura konfiguratora zintegrowanego przez API
- Synchronizacja danych: real-time, cykliczna czy hybrydowa
- Jak zaprojektować mapowanie pól i reguły biznesowe
- Panel administracyjny do obsługi integracji
- Bezpieczeństwo, wydajność i odporność na błędy API
- Plan wdrożenia krok po kroku
- Najczęstsze błędy przy wdrażaniu konfiguratora z API
- Kiedy warto połączyć konfigurator z innymi typami automatyzacji
Dlaczego konfigurator produktów powinien korzystać z API
Nie każdy konfigurator musi być zasilany zewnętrznymi systemami, ale w wielu projektach API staje się podstawą działania. Jeśli oferta zmienia się często, dane pochodzą z kilku źródeł, a ręczna aktualizacja jest zbyt wolna lub ryzykowna, integracja przez API przestaje być dodatkiem i staje się koniecznością.
Największą wartością takiego podejścia jest to, że konfigurator pokazuje użytkownikowi aktualny stan biznesowy: prawidłowe ceny, dostępność, ograniczenia techniczne, warianty i reguły zależności. Dzięki temu sprzedaż nie opiera się na nieaktualnych danych, a zespół nie musi poprawiać oferty ręcznie w CMS-ie lub panelu sklepu.
- Oferta zmienia się często i wymaga automatycznej aktualizacji.
- Dane są rozproszone w ERP, PIM, magazynie lub systemie producenta.
- Konfigurator ma pokazywać ceny, stany i ograniczenia w czasie zbliżonym do rzeczywistego.
- Zespół chce ograniczyć ręczną pracę przy edycji produktów.
- Produkt ma zależności techniczne, które trzeba walidować na bieżąco.
Jakie dane powinny przepływać między systemami a konfiguratoriem
Najczęstszy błąd to zaczynanie od interfejsu bez ustalenia, jakie dane faktycznie mają być pobierane i jak mają być interpretowane. Konfigurator może potrzebować nie tylko nazwy i ceny, ale też parametrów technicznych, komponentów, ograniczeń kompatybilności, stanów magazynowych, progów cenowych i plików pomocniczych.
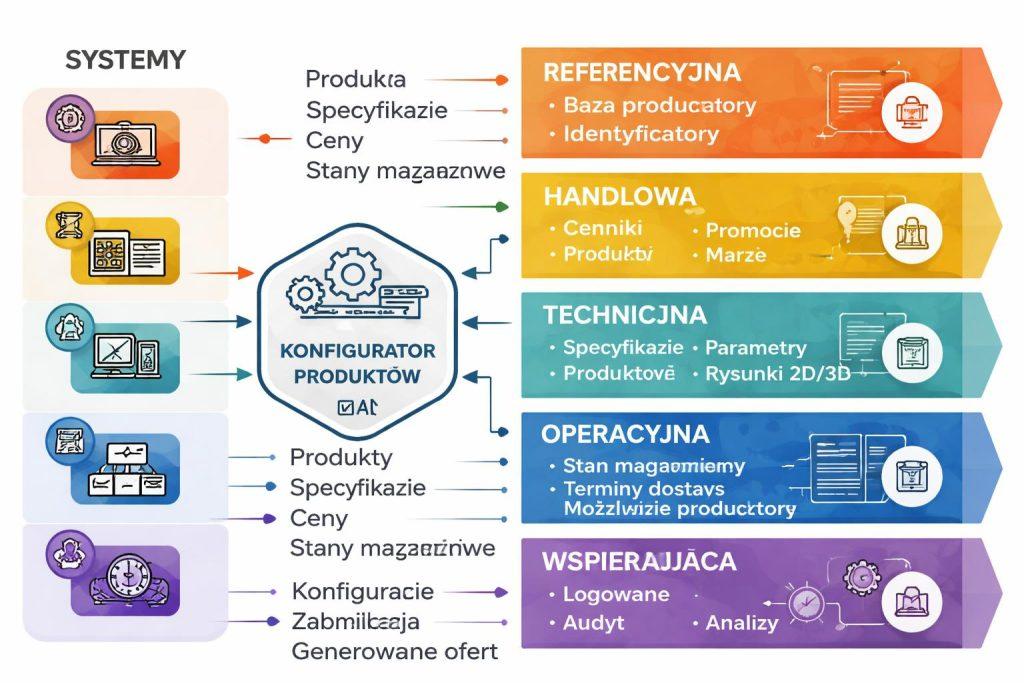
W praktyce najlepiej podzielić dane na kilka grup: referencyjne, handlowe, techniczne, operacyjne oraz wspierające. Każda z nich może pochodzić z innego systemu, dlatego potrzebne są mapowanie, walidacja i ustalenie źródła prawdy dla każdego typu informacji.
Warto też od razu przewidzieć wersjonowanie struktury danych. Jeśli zewnętrzne API zmieni format odpowiedzi, konfigurator nie powinien przestać działać z dnia na dzień. Pomagają w tym walidacja schematu, fallbacki oraz mechanizmy wykrywania brakujących pól.
- Dane referencyjne: nazwa, identyfikator, opis, kategoria.
- Dane handlowe: cena, waluta, rabat, progi cenowe.
- Dane techniczne: parametry, kompatybilność, ograniczenia.
- Dane operacyjne: dostępność, czas realizacji, status.
- Dane wspierające: zdjęcia, dokumentacja, pliki do pobrania.
Architektura konfiguratora zintegrowanego przez API
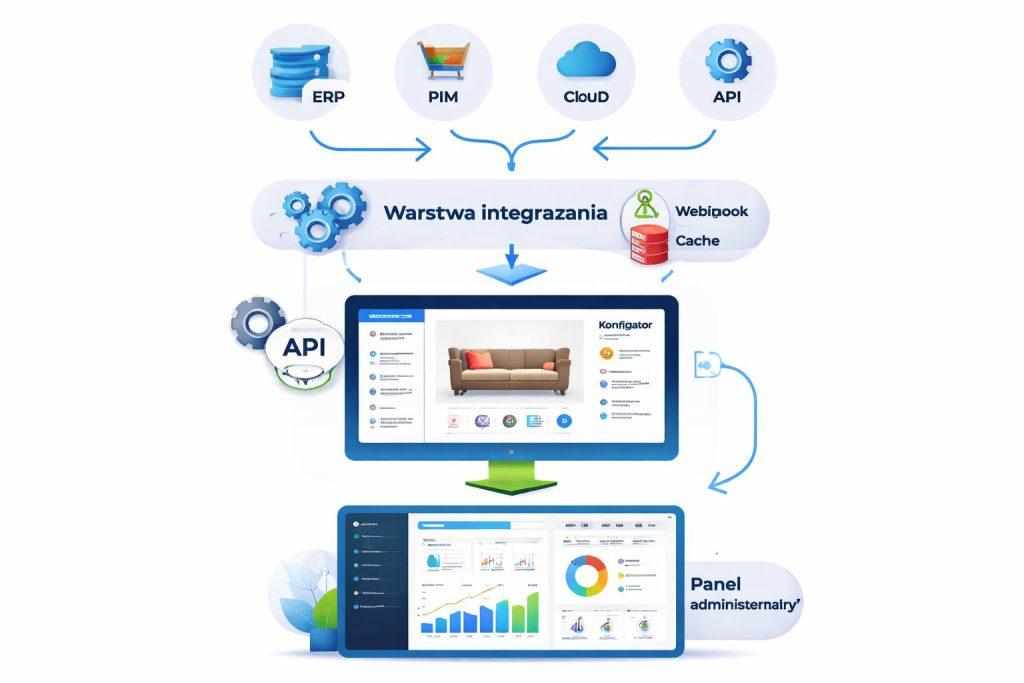
Najstabilniejsze wdrożenia opierają się na rozdzieleniu trzech warstw: źródeł danych, warstwy integracyjnej i interfejsu konfiguratora. Taki układ pozwala uniknąć sytuacji, w której frontend bezpośrednio komunikuje się z wieloma systemami, co szybko staje się trudne w utrzymaniu.
Warstwa integracyjna pełni rolę adaptera. Pobiera dane z różnych API, normalizuje je do jednego modelu, waliduje i udostępnia konfiguratorowi spójny zestaw informacji. To szczególnie ważne wtedy, gdy jeden system zwraca ceny w innym formacie, drugi opisuje warianty inaczej, a trzeci ma ograniczony zestaw endpointów.
Przy większej skali projektu warto dodać cache, kolejki zadań i webhooki. Dzięki temu konfigurator reaguje szybciej, nie obciąża źródeł danych i lepiej znosi chwilowe awarie systemów zewnętrznych.
- Źródła danych: ERP, PIM, CRM, magazyn, system producenta.
- Warstwa integracyjna: adaptery, mapowanie, walidacja, cache.
- Frontend konfiguratora: prezentacja opcji, zależności i wyceny.
- Panel administracyjny: monitoring synchronizacji i ręczne korekty.
- Mechanizmy awaryjne: fallback, logowanie, retry, alerty.
Synchronizacja danych: real-time, cykliczna czy hybrydowa
Wybór modelu synchronizacji zależy od tego, jak krytyczna jest świeżość danych. Jeśli użytkownik musi widzieć aktualną dostępność albo cenę w momencie konfiguracji, potrzebne mogą być webhooki lub odpytywanie API przy konkretnym zdarzeniu. Jeśli zmiany są rzadsze, wystarczy synchronizacja cykliczna.
W wielu projektach najlepiej sprawdza się model hybrydowy. Dane podstawowe są aktualizowane cyklicznie, a informacje krytyczne są odświeżane na żądanie albo przez webhook. To daje równowagę między wydajnością, dokładnością i odpornością na awarie.
Warto też pamiętać, że synchronizacja to decyzja biznesowa, nie tylko techniczna. Czasem lepiej jest pokazać ostatnią poprawną wartość niż zablokować cały proces konfiguracji. Kluczowe jest jednak jasne oznaczenie, kiedy dane zostały odświeżone.
- Webhooki do natychmiastowych zmian.
- Polling dla cyklicznego odświeżania danych.
- Cache dla ograniczenia liczby zapytań.
- Model hybrydowy jako najbezpieczniejsze rozwiązanie w praktyce.
- Widoczny czas ostatniej synchronizacji w panelu administracyjnym.
Jak zaprojektować mapowanie pól i reguły biznesowe
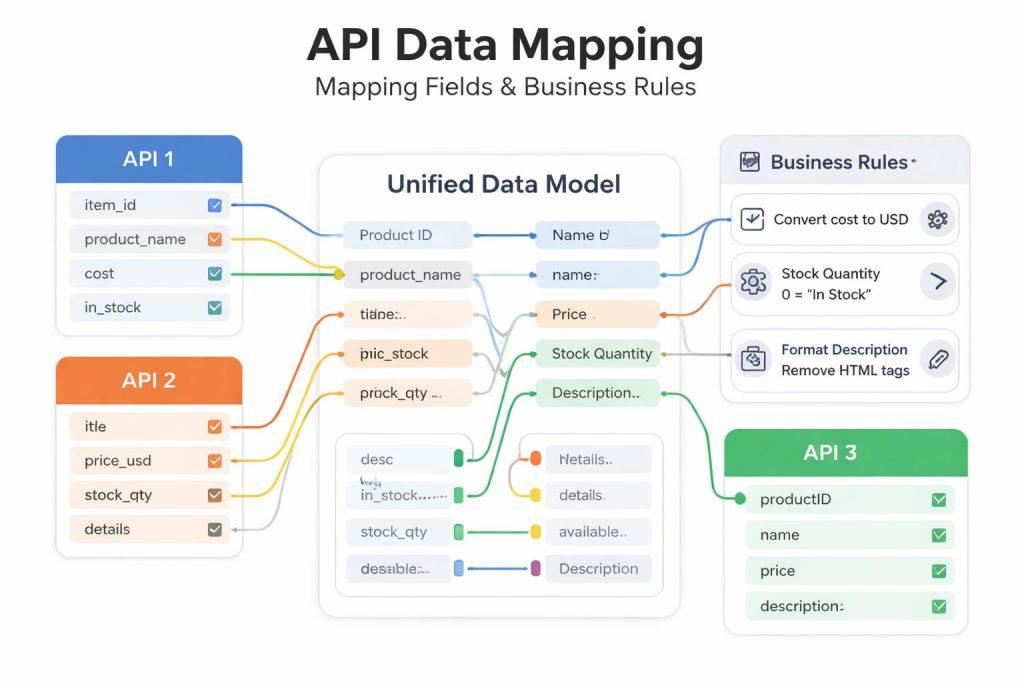
Mapowanie pól to miejsce, w którym najczęściej pojawiają się błędy wdrożeniowe. Jeśli jedno API zwraca identyfikatory, drugie nazwy handlowe, a trzecie zagnieżdżone obiekty komponentów, trzeba zbudować spójny model pośredni. To on powinien zasilać konfigurator, a nie surowe odpowiedzi z zewnętrznych systemów.
Na tym etapie trzeba też opisać reguły biznesowe. Konfigurator nie ma tylko wyświetlać danych, ale też ograniczać wybory użytkownika, blokować niekompatybilne opcje i przeliczać cenę lub dostępność w odpowiednim momencie. Bez tego szybko powstaje chaos w danych i błędne konfiguracje.
Dobre praktyki zakładają trzymanie części reguł poza kodem, jeśli to możliwe. Dzięki temu administrator może zmieniać wybrane zależności bez angażowania programisty przy każdej korekcie.
- Ustal jeden model danych pośrednich.
- Zdefiniuj mapowanie pól dla każdego źródła API.
- Opisz reguły kompatybilności, wykluczeń i zależności.
- Oddziel dane od logiki biznesowej.
- Przewiduj wersjonowanie reguł i zmian struktury danych.
Panel administracyjny do obsługi integracji
Panel administracyjny nie jest dodatkiem, tylko jednym z najważniejszych elementów całego rozwiązania. To właśnie tam zespół powinien widzieć status synchronizacji, błędy integracji, ostatnie pobrania danych oraz możliwość ręcznego odświeżenia wybranych sekcji oferty.
Warto przewidzieć widok jakości danych. Administrator powinien łatwo sprawdzić, które rekordy nie przeszły walidacji, które pola są nieuzupełnione i które produkty wymagają interwencji. Bez tego każdy problem z API kończy się szukaniem przyczyny w logach technicznych.
Dobry panel pozwala także kontrolować wyjątki. Część produktów może mieć indywidualne nadpisania, część danych może być blokowana przed automatyczną aktualizacją, a wybrane ceny mogą wymagać akceptacji. To porządkuje pracę zespołu zamiast odbierać mu kontrolę.
- Status ostatniej synchronizacji.
- Lista błędów i ostrzeżeń.
- Ręczne odświeżenie danych.
- Nadpisania i wyjątki dla wybranych produktów.
- Podgląd logów i historii zmian.
Bezpieczeństwo, wydajność i odporność na błędy API
Integracje trzeba projektować tak, jakby część z nich miała czasem zawieść, bo w praktyce to normalne. Błędy autoryzacji, timeouty, limity zapytań, niepełne odpowiedzi czy chwilowa niedostępność usług zewnętrznych powinny być przewidziane od początku.
Dlatego ważne są cache, kolejki i mechanizmy ponawiania. W wielu przypadkach lepiej chwilowo pokazać ostatnią poprawną wartość niż zablokować cały proces konfiguracji. Jednocześnie trzeba jasno oznaczać, kiedy dane pochodzą z odświeżenia sprzed chwili, a kiedy z bieżącego zapytania.
Równie istotne są kwestie bezpieczeństwa. API powinno być zabezpieczone kluczami, tokenami i ograniczeniami zakresu dostępu. Warto też zadbać o separację uprawnień i niewystawianie wrażliwych danych do frontendu, jeśli nie są potrzebne użytkownikowi końcowemu.
- Obsługa timeoutów i retry.
- Cache dla danych mniej krytycznych.
- Rate limiting i kontrola limitów API.
- Bezpieczna autoryzacja i rotacja kluczy.
- Monitoring błędów oraz alerty techniczne.
Plan wdrożenia krok po kroku
Najbezpieczniej wdrażać taki projekt etapami. Najpierw trzeba zebrać wymagania biznesowe, opisać źródła danych i ustalić, co dokładnie ma być synchronizowane. Potem projektuje się model danych, reguły biznesowe i sposób aktualizacji, a dopiero na końcu buduje frontend konfiguratora oraz panel administracyjny.
Kolejnym krokiem są testy integracyjne. Trzeba sprawdzić nie tylko poprawne scenariusze, ale także błędy API, niekompletne dane, konflikty reguł, opóźnienia synchronizacji i zachowanie systemu przy dużej liczbie zapytań. To właśnie tu wychodzą problemy, które w produkcji byłyby najdroższe.
Na końcu warto wdrażać rozwiązanie etapowo. Zwykle lepiej uruchomić konfigurator na wybranej części katalogu lub na środowisku testowym z prawdziwymi danymi niż od razu podmieniać całą ofertę.
- Analiza źródeł danych i zakresu integracji.
- Projekt modelu danych i mapowania.
- Implementacja warstwy integracyjnej.
- Budowa konfiguratora i panelu admina.
- Testy integracyjne, wydajnościowe i biznesowe.
- Wdrożenie etapowe i obserwacja po starcie.
Najczęstsze błędy przy wdrażaniu konfiguratora z API
Najczęstszy błąd to traktowanie API jako technicznego dodatku, a nie fundamentu działania konfiguratora. Bez jasno opisanych źródeł prawdy i mapowania pól system bardzo szybko zaczyna produkować niespójne dane.
Drugim problemem jest zbyt mocne związanie frontendu z zewnętrznymi systemami. Jeśli interfejs pobiera dane bezpośrednio z kilku API, utrzymanie, testowanie i rozwój stają się trudne oraz podatne na awarie.
Błędem jest też brak obsługi wyjątków biznesowych. Nawet najlepsza integracja techniczna nie rozwiąże problemu, jeśli nie da się oznaczyć produktów blokowanych, nadpisywanych lub wymagających ręcznej akceptacji.
- Brak jednego modelu danych pośrednich.
- Bezpośrednie łączenie frontu z wieloma API.
- Brak walidacji danych i reguł biznesowych.
- Brak panelu do nadpisywania wyjątków.
- Brak monitoringu i alertów po wdrożeniu.
Kiedy warto połączyć konfigurator z innymi typami automatyzacji
Konfigurator z API bardzo dobrze łączy się z innymi rozwiązaniami automatyzującymi sprzedaż i obsługę katalogu. W praktyce często współpracuje z importem CSV, panelami do zarządzania wariantami, konfiguratorami 3D, systemami ofertowania i mechanizmami zapytań ofertowych.
Takie połączenie daje większą elastyczność. Część danych można aktualizować masowo z plików, część pobierać z systemów zewnętrznych, a część nadpisywać ręcznie w panelu administracyjnym. To dobre podejście zwłaszcza wtedy, gdy oferta jest złożona, ale nie wszystkie dane istnieją w jednym systemie.
Jeśli projekt wymaga wizualizacji, warto rozważyć również konfigurator 3D z API. Wtedy logika danych pozostaje wspólna, a różni się tylko warstwa prezentacji.
- Konfigurator 3D z automatyzacją danych.
- Importy CSV jako wsparcie dla masowych aktualizacji.
- Zapytania ofertowe zamiast klasycznego koszyka.
- Panel administracyjny do zarządzania wariantami.
- Integracja z B2B i wyceną indywidualną.
Checklist
- Zidentyfikuj wszystkie systemy źródłowe i ustal, który jest źródłem prawdy dla poszczególnych danych.
- Określ zakres informacji pobieranych przez API: ceny, stany, parametry, komponenty, ograniczenia, opisy i pliki.
- Zaprojektuj jednolity model danych pośrednich dla konfiguratora.
- Zdefiniuj mapowanie pól między systemami i zasady wersjonowania.
- Wybierz model synchronizacji: webhooki, polling, cache lub rozwiązanie hybrydowe.
- Dodaj walidację danych, retry, fallbacki i logowanie błędów.
- Przygotuj panel administracyjny z historią synchronizacji i ręcznym odświeżaniem.
- Przetestuj scenariusze brzegowe: brak danych, timeouty, duplikaty, niepełne odpowiedzi i konflikty reguł.
- Wdroż monitoring, alerty i dokumentację dla zespołu.
- Uruchom konfigurator etapowo, zaczynając od wybranego fragmentu katalogu lub środowiska testowego.
FAQ
Jakie systemy najczęściej integruje się z konfiguratorami produktów przez API?
Najczęściej integruje się ERP, PIM, systemy magazynowe, bazy cenników, CRM, katalogi dostawców oraz systemy wyceny i obsługi zamówień. W większych wdrożeniach dane pochodzą z kilku źródeł jednocześnie.
Czy konfigurator może pobierać ceny i dostępność w czasie rzeczywistym?
Tak, ale tylko wtedy, gdy system źródłowy to obsługuje i nie obciąża to nadmiernie infrastruktury. W praktyce często lepszy jest model hybrydowy: cache, webhooki i okresowa synchronizacja dla danych mniej krytycznych.
Co jest ważniejsze: frontend konfiguratora czy integracja z API?
Na początku ważniejsza jest integracja i model danych, bo to one decydują, jakie opcje, ceny i ograniczenia da się poprawnie wyświetlić. Frontend powinien opierać się na stabilnej warstwie danych, a nie na surowych odpowiedziach z API.
Jak uniknąć rozjazdu danych między sklepem a systemem zewnętrznym?
Trzeba ustalić jeden system źródłowy dla każdego typu danych, wdrożyć mapowanie pól, walidację, logi synchronizacji, mechanizmy retry oraz panel do kontroli wyjątków i ręcznych korekt.
Czy taki konfigurator sprawdzi się w B2B?
Tak, szczególnie w B2B, gdzie ceny są indywidualne, oferta często się zmienia, a produkty mają wiele zależności technicznych i handlowych. Integracja przez API bardzo ułatwia utrzymanie aktualności danych.
Podsumowanie
Wdrożenie konfiguratora produktów zasilanego danymi zewnętrznymi przez API wymaga przede wszystkim dobrej architektury integracyjnej, a nie samego frontendu. Kluczowe są: model danych, mapowanie pól, synchronizacja, walidacja, panel administracyjny oraz odporność na błędy po stronie systemów źródłowych. Jeśli projekt od początku uwzględnia źródła prawdy, reguły biznesowe, monitoring i scenariusze awaryjne, konfigurator aktualizuje ofertę automatycznie i realnie odciąża zespół sprzedaży oraz administracji.


