Praktyczny przewodnik po wdrożeniu konfiguratora z importem z arkuszy i plików CSV. Sprawdź, jak zaprojektować model danych, mapowanie kolumn, walidację, wersjonowanie zmian oraz bezpieczną masową aktualizację opcji, cen i komponentów.
Najlepszy konfigurator z importem danych z arkuszy i CSV opiera się na jednym modelu danych, mapowaniu kolumn, walidacji, wersjonowaniu i podglądzie zmian przed publikacją. Dzięki temu można bezpiecznie masowo aktualizować opcje, ceny i komponenty oraz synchronizować dane z ERP, PIM lub innym systemem źródłowym.
Najważniejsze wnioski
- Najpierw projektuje się model danych, dopiero potem format importu.
- CSV sprawdza się najlepiej w automatyzacji, a arkusz w pracy operacyjnej.
- Mapowanie kolumn i walidacja są kluczowe dla bezbłędnego importu.
- Masową aktualizację warto dzielić na osobne sekcje: opcje, ceny, komponenty i zależności.
- Wersjonowanie i podgląd zmian przed publikacją ograniczają ryzyko błędów.
- Konfigurator powinien mieć jasno określone źródło prawdy dla danych.
- Panel administracyjny musi wspierać filtry, historię zmian i szybkie poprawki.
- Integracja z ERP lub PIM znacząco ułatwia utrzymanie aktualności danych.
- Dlaczego konfigurator oparty na arkuszach i CSV ma sens biznesowo
- Jak zaprojektować model danych przed importem
- CSV, arkusz czy model hybrydowy
- Mapowanie kolumn i walidacja danych bez chaosu
- Masowa aktualizacja opcji, cen i komponentów w praktyce
- Synchronizacja z ERP, PIM i innymi źródłami prawdy
- Panel administracyjny, który naprawdę ułatwia życie
- Proces wdrożenia krok po kroku i typowe pułapki
Dlaczego konfigurator oparty na arkuszach i CSV ma sens biznesowo
W wielu firmach największym problemem nie jest sam konfigurator, ale utrzymanie danych. Gdy rośnie liczba opcji, cen, komponentów i wyjątków, ręczna edycja w panelu staje się zbyt wolna i podatna na błędy.
Import z arkuszy i plików CSV przenosi pracę tam, gdzie zespół biznesowy i produktowy faktycznie działa na co dzień. To skraca czas aktualizacji, zmniejsza liczbę pomyłek i pozwala sprawniej obsługiwać asortyment sezonowy, konfigurowalny lub wymagający indywidualnych wycen.
Takie podejście szczególnie dobrze działa w e-commerce i B2B, gdzie produkty są złożone, a oferta zależy od stanu magazynowego, segmentu klienta, dostępnych komponentów lub reguł technicznych.
- mniej ręcznej pracy administracyjnej
- szybsza aktualizacja cenników i wariantów
- lepsza kontrola nad błędami danych
- łatwiejsze skalowanie katalogu produktów
Jak zaprojektować model danych przed importem
Najczęstszy błąd polega na zaczynaniu od importu, zanim zostanie ustalona struktura danych. Najpierw trzeba określić, co jest produktem bazowym, czym są opcje, jakie elementy są komponentami, a które dane stanowią reguły biznesowe.
Dobrze zaprojektowany model danych powinien mieć stabilne identyfikatory, jednoznaczne relacje i jasny podział odpowiedzialności. Produkt, wariant, komponent, cena, dostępność i ograniczenia nie mogą być traktowane jako jeden wspólny zbiór wpisów.
Warto też od razu zdecydować, które dane są edytowane przez biznes, a które przez developerów lub integrację. To minimalizuje ryzyko nadpisania reguł i zerwania zależności między wariantami.
- zdefiniuj główny identyfikator produktu i wariantu
- oddziel dane opisowe od reguł i zależności
- ustal pola obowiązkowe
- przypisz właściciela do każdego typu danych
CSV, arkusz czy model hybrydowy
CSV jest zwykle najlepszy do automatyzacji, integracji i cyklicznych importów. Jest prosty technicznie i stabilny, ale mniej wygodny dla osób nietechnicznych, zwłaszcza przy dużej liczbie kolumn i zależności.
Arkusz kalkulacyjny jest wygodniejszy dla zespołów operacyjnych. Ułatwia edycję, komentarze i pracę w znanym środowisku, ale niesie większe ryzyko błędów formatowania i problemów z wersjonowaniem.
W praktyce najlepiej sprawdza się model hybrydowy: arkusz do przygotowania i akceptacji danych, a CSV lub API do właściwego importu do systemu.
- CSV do automatyzacji i synchronizacji
- arkusz do edycji i akceptacji
- API do importów cyklicznych lub czasu rzeczywistego
- walidacja niezależna od formatu wejściowego
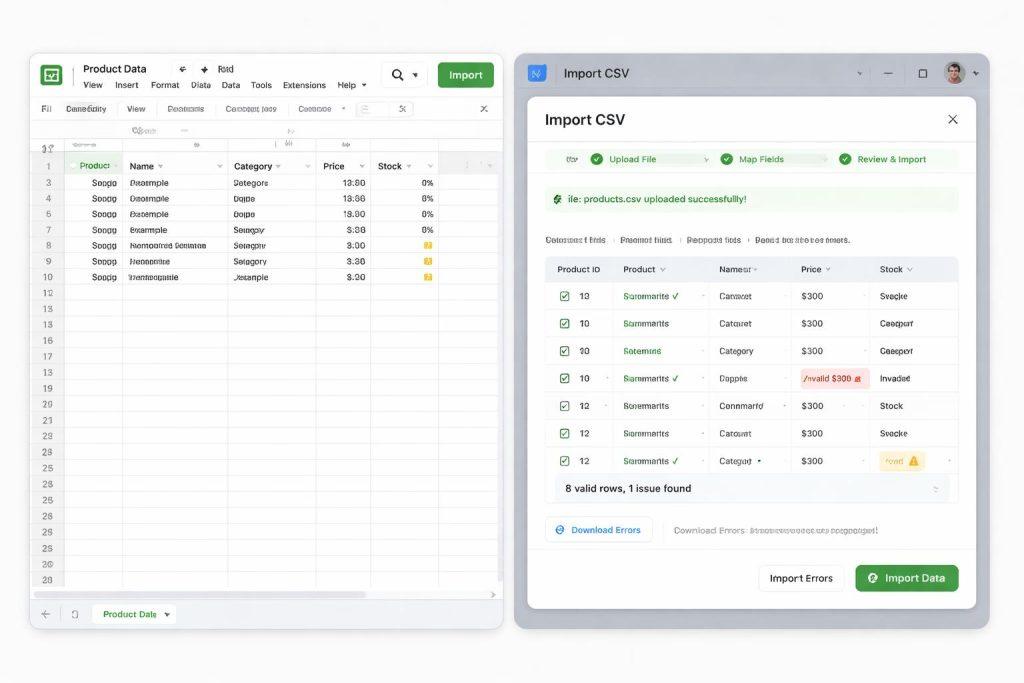
Mapowanie kolumn i walidacja danych bez chaosu
Samo wczytanie pliku to dopiero początek. Prawdziwa wartość pojawia się wtedy, gdy system potrafi zmapować kolumny z arkusza do pól konfiguratora i zapisać to mapowanie jako szablon do ponownego użycia.
Walidacja powinna sprawdzać nie tylko obecność danych, ale też ich sens. Inna cena nie może trafić do niewłaściwego komponentu, opcja nie może wskazywać nieistniejącego wariantu, a reguły zależności nie mogą tworzyć pętli lub sprzeczności.
Dobrą praktyką jest podgląd importu przed publikacją. System powinien pokazać, co zostanie dodane, zmienione lub usunięte, a administrator powinien mieć możliwość zatwierdzenia albo odrzucenia paczki zmian.
- mapowanie kolumn zapisuj jako szablon importu
- sprawdzaj wymagane pola i typy danych
- wykrywaj duplikaty identyfikatorów
- pokazuj podgląd zmian przed publikacją
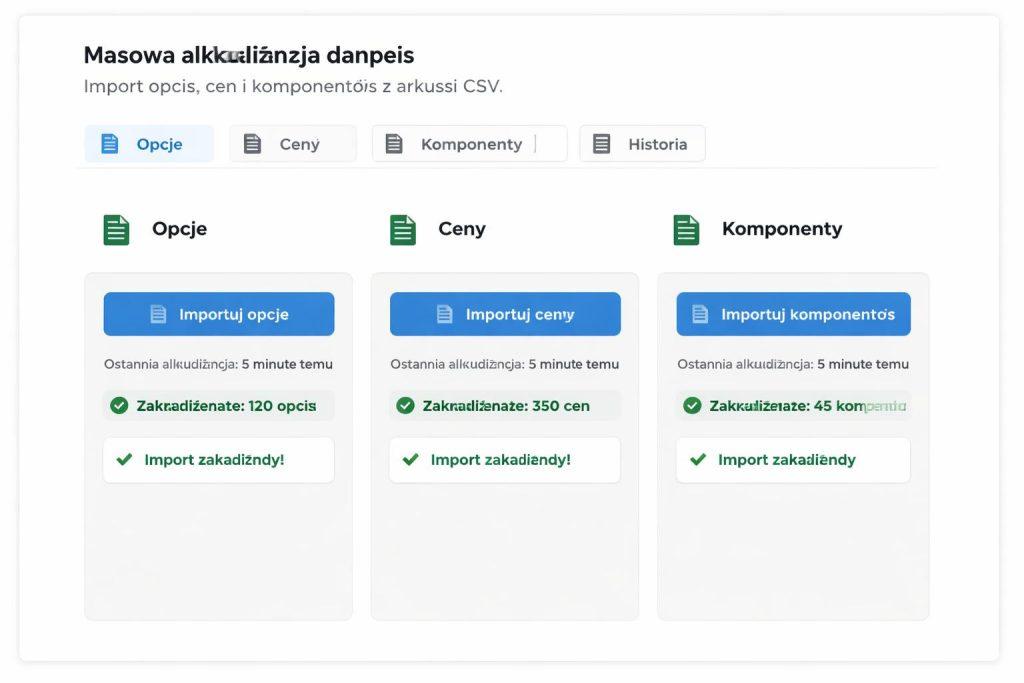
Masowa aktualizacja opcji, cen i komponentów w praktyce
W konfiguratorze najbardziej wrażliwe są trzy obszary: opcje, ceny i komponenty. Opcje wpływają na wybór użytkownika, ceny na marżę, a komponenty na wykonalność konfiguracji, dlatego masowa aktualizacja musi być szybka i bezpieczna.
Najlepiej podzielić import na sekcje. Inny zestaw danych aktualizuje warianty, inny cenniki, a jeszcze inny zależności komponentów. Dzięki temu jedna błędna zmiana nie psuje całej struktury.
Warto przewidzieć także aktualizację częściową, czyli możliwość zmiany tylko wybranej grupy danych bez przepisywania pełnego katalogu. To szczególnie ważne przy dużych projektach i częstych zmianach ofertowych.
- oddziel aktualizację opcji od aktualizacji cen
- wprowadź import częściowy dla wybranych danych
- zapisuj historię zmian i autora importu
- umożliw cofnięcie paczki zmian
Synchronizacja z ERP, PIM i innymi źródłami prawdy
Jeśli firma korzysta z ERP, PIM albo systemu hurtowego, konfigurator nie powinien działać w izolacji. Trzeba ustalić, który system jest źródłem prawdy dla cen, stanów, opisów i atrybutów, a który odpowiada za reguły konfiguracji i prezentację.
Integracja może działać cyklicznie albo zdarzeniowo. W pierwszym wariancie dane są pobierane okresowo i aktualizowane partiami. W drugim system reaguje niemal od razu na zmianę w ERP lub PIM przez webhook, kolejkę zadań lub API.
Najlepsze wdrożenia rozdzielają odpowiedzialność między systemy. ERP dostarcza ceny i dostępność, PIM opisy i atrybuty, a konfigurator logikę wyboru oraz warstwę prezentacji.
- ustal system nadrzędny dla każdej grupy danych
- zdecyduj między synchronizacją cykliczną a zdarzeniową
- loguj błędy integracji i nieudane importy
- nie dubluj ręcznie tych samych danych w kilku miejscach
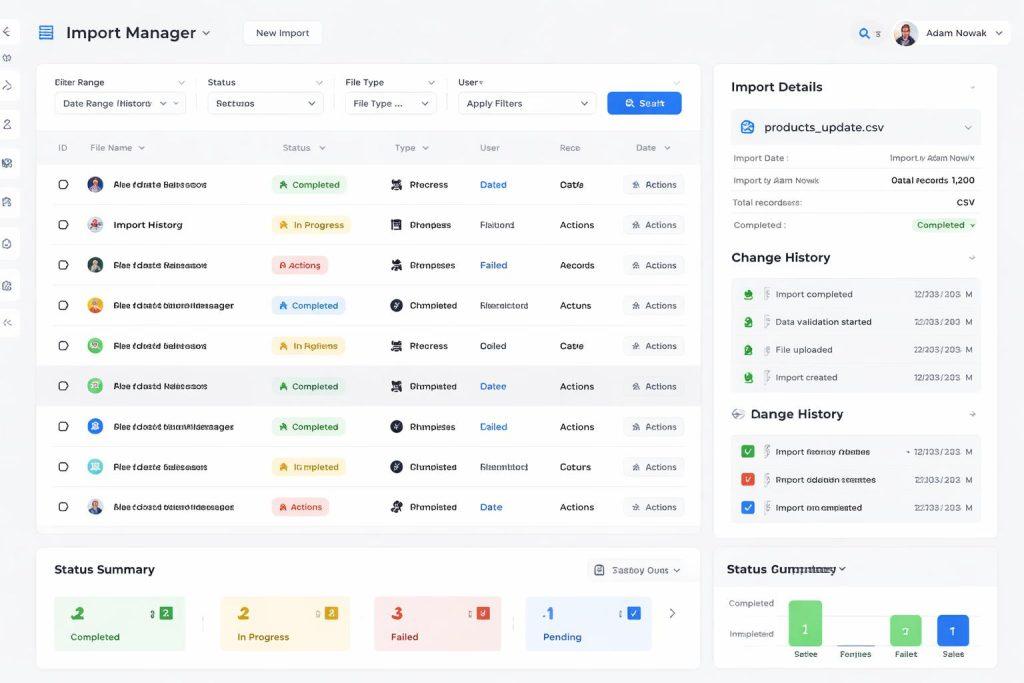
Panel administracyjny, który naprawdę ułatwia życie
Nawet najlepszy import nie uratuje projektu, jeśli panel będzie nieczytelny. Osoba zarządzająca konfiguracją musi szybko znaleźć produkt, zrozumieć zależności i wykonać korektę bez zgadywania.
Dobry panel powinien wspierać filtry, masowe akcje, wersje danych i prostą nawigację po strukturze. Ważna jest też separacja widoków, bo inaczej pracuje osoba od cenników, inaczej content manager, a inaczej administrator techniczny.
W praktyce krytyczne okazują się też funkcje mniej widowiskowe: wyszukiwarka po identyfikatorach, status importu, lista błędów, eksport bieżącej konfiguracji i porównanie wersji.
- wyszukiwarka i filtry po produktach oraz komponentach
- podgląd historii zmian i wersji
- masowe akcje na wybranych rekordach
- czytelne komunikaty błędów importu
Proces wdrożenia krok po kroku i typowe pułapki
Wdrożenie warto prowadzić etapami. Najpierw należy zebrać wymagania, potem zaprojektować model danych, przygotować format importu, zbudować walidację i dopiero później połączyć to z frontem konfiguratora.
Kolejny krok to testy na realnych danych. Dopiero wtedy widać problemy z brakującymi identyfikatorami, niekompletnymi zależnościami i różnymi wariantami nazewnictwa. Test importu na próbce danych powinien być obowiązkowy.
Najczęstsze pułapki to brak wersjonowania, zbyt skomplikowany format pliku, brak odpowiedzialności za dane i próba odwzorowania całej logiki biznesowej w samym arkuszu.
- zacznij od modelu danych, nie od interfejsu
- przetestuj import na realnym katalogu produktowym
- wprowadź wersje i możliwość cofania zmian
- unikaj nadmiernego komplikowania plików źródłowych
Checklist
- Zdefiniuj, które dane mają pochodzić z arkusza: opcje, ceny, komponenty, ograniczenia i dostępność.
- Ustal jeden identyfikator dla produktu, wariantu i komponentu.
- Zaprojektuj model danych przed definiowaniem formatu importu.
- Przygotuj mapowanie kolumn z arkusza lub CSV do pól systemowych.
- Dodaj walidację typów danych, zakresów i zależności między rekordami.
- Wprowadź podgląd importu przed zapisaniem zmian.
- Zaimplementuj wersjonowanie danych i historię zmian.
- Zdecyduj, które dane synchronizują się automatycznie, a które po akceptacji.
- Testuj import na realnych danych w środowisku testowym.
- Upewnij się, że panel administracyjny umożliwia szybkie poprawki i ponowny import.
- Połącz konfigurator z analityką, aby mierzyć użycie wariantów i błędy konfiguracji.
FAQ
Czy konfigurator można zasilać danymi bezpośrednio z Excela?
Tak, ale Excel najlepiej traktować jako narzędzie do przygotowania i akceptacji danych, a nie jako jedyne źródło prawdy. Bezpieczniejszy model to import do uporządkowanej bazy w systemie, gdzie dane przechodzą walidację, wersjonowanie i publikację po akceptacji.
CSV czy arkusz — co lepiej sprawdza się przy konfiguratorze?
CSV lepiej nadaje się do automatyzacji, integracji i cyklicznych importów. Arkusz jest wygodniejszy dla zespołów biznesowych, które pracują ręcznie na danych. W praktyce najczęściej najlepiej działa model hybrydowy: arkusz do przygotowania, CSV lub API do importu.
Jak uniknąć błędów przy masowej aktualizacji cen i opcji?
Trzeba wdrożyć walidację pliku, spójne identyfikatory, wykrywanie duplikatów, podgląd zmian przed publikacją oraz możliwość cofnięcia paczki zmian. Dobrym standardem jest też test importu na środowisku testowym.
Czy taki konfigurator da się połączyć z ERP lub PIM?
Tak, i zwykle jest to najlepsze rozwiązanie. ERP lub PIM może dostarczać ceny, stany, opisy i atrybuty, a konfigurator odpowiada za logikę wyboru, prezentację i reguły konfiguracji. Kluczowe jest ustalenie źródła prawdy dla każdej grupy danych.
Kiedy lepiej zbudować własny mechanizm importu niż używać gotowej wtyczki?
Własny mechanizm warto wybrać wtedy, gdy konfigurator ma złożone reguły, wiele zależności, częste aktualizacje albo integracje z ERP, PIM lub innymi systemami. Gotowe wtyczki sprawdzają się głównie w prostych scenariuszach bez rozbudowanej logiki biznesowej.
Podsumowanie
Artykuł pokazuje, jak wdrożyć konfigurator produktów oparty na imporcie danych z arkuszy i plików CSV, tak aby możliwa była bezpieczna i skalowalna aktualizacja opcji, cen oraz komponentów. Omawia projekt modelu danych, formaty importu, mapowanie kolumn, walidację, wersjonowanie, integrację z ERP/PIM, panel administracyjny i praktyczny proces wdrożenia krok po kroku.


