Praktyczny przewodnik po wdrożeniu konfiguratora produktów w modelu headless commerce. Sprawdź, kiedy takie podejście ma sens, jak zaprojektować architekturę, model danych i integracje oraz jak połączyć frontend z API bez utraty wydajności i kontroli nad logiką sprzedaży.
Konfigurator produktów w headless commerce ma sens wtedy, gdy oferta jest złożona, dynamiczna i wymaga wielu integracji. Najlepiej działa, gdy frontend odpowiada za prezentację i prowadzenie użytkownika, a backend za reguły, walidację, ceny, dostępność i kompatybilność komponentów. Kluczem jest warstwa API, która porządkuje dane z PIM, ERP, magazynu i innych systemów.
Najważniejsze wnioski
- Headless commerce opłaca się przy złożonych konfiguratorach, wielu źródłach danych i potrzebie rozwoju na kilku kanałach.
- Frontend powinien być lekki i pobierać tylko dane potrzebne w danym kroku konfiguracji.
- Backend musi być źródłem prawdy dla reguł, walidacji, cen i kompatybilności.
- Warstwa integracyjna upraszcza połączenie z PIM, ERP, magazynem i innymi systemami.
- Dobry model danych skraca czas wdrożenia i ogranicza kosztowny refaktoring.
- UX konfiguratora powinien prowadzić użytkownika krok po kroku i minimalizować liczbę decyzji naraz.
- Wdrożenie warto prowadzić etapowo: analiza, model danych, architektura API, prototyp, implementacja, testy i monitoring.
- Dlaczego konfigurator produktów i headless commerce dobrze się uzupełniają
- Kiedy headless ma sens, a kiedy lepiej wybrać prostsze rozwiązanie
- Jak zaprojektować model danych dla konfiguratora
- Jak połączyć frontend z API bez utraty wydajności
- Logika konfiguracji i walidacja po stronie backendu
- Jak zaplanować UX konfiguratora w środowisku headless
- Integracje z ERP, PIM, magazynem i innymi systemami
- Plan wdrożenia krok po kroku
- Najczęstsze błędy przy wdrażaniu konfiguratora headless
- Jak połączyć konfigurator z wyceną i danymi z API
- Jak utrzymać konfigurator po wdrożeniu
Dlaczego konfigurator produktów i headless commerce dobrze się uzupełniają
Konfigurator produktów potrzebuje elastyczności: wielu wariantów, zależności między opcjami, dynamicznych cen oraz często także integracji z innymi systemami. Właśnie dlatego architektura headless commerce bardzo dobrze pasuje do takich projektów, bo oddziela warstwę prezentacji od logiki biznesowej.
Dzięki temu frontend można projektować niezależnie od silnika sklepu, a sam interfejs lepiej dopasować do procesu decyzyjnego użytkownika. To szczególnie ważne wtedy, gdy konfigurator ma prowadzić klienta krok po kroku, a nie tylko wyświetlać listę opcji.
- rozdzielenie frontendu i backendu
- spójne dane dla wielu kanałów sprzedaży
- łatwiejsze rozwijanie interfejsu
- lepsze dopasowanie do złożonych reguł konfiguracji
Kiedy headless ma sens, a kiedy lepiej wybrać prostsze rozwiązanie
Headless commerce nie jest automatycznie najlepszym wyborem. Jeśli produkt ma tylko kilka prostych wariantów, a konfiguracja nie wpływa znacząco na cenę, dostępność ani logikę sprzedaży, pełna przebudowa architektury może być nieopłacalna.
Headless zaczyna wygrywać wtedy, gdy konfigurator musi obsługiwać wiele reguł kompatybilności, dynamiczne ceny, dane z ERP lub PIM oraz działać na kilku kanałach sprzedaży. To także dobry kierunek, gdy zespół chce niezależnie rozwijać frontend bez czekania na zmiany po stronie całej platformy.
- duża liczba wariantów i zależności
- wiele źródeł danych i integracji
- potrzeba rozwoju na kilku kanałach
- wymóg niezależnego rozwoju frontendów
- mała złożoność produktu i niski budżet jako sygnał ostrożności
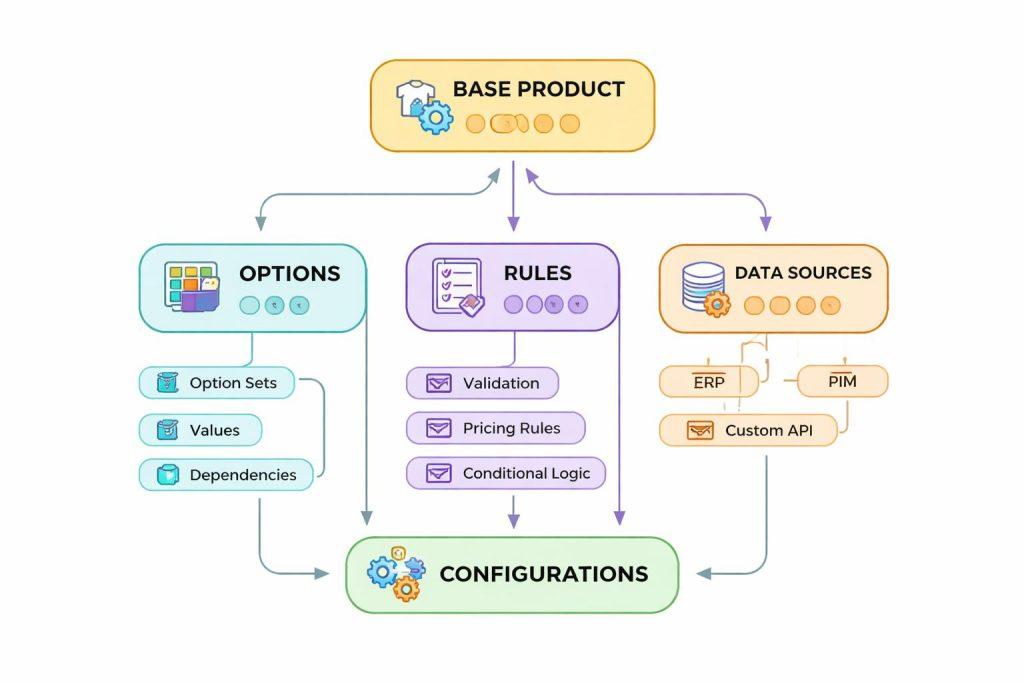
Jak zaprojektować model danych dla konfiguratora
Dobry konfigurator zaczyna się od modelu danych, a nie od interfejsu. Trzeba zdefiniować produkt bazowy, opcje, warianty, reguły zależności, źródła cen, statusy dostępności i pola wymagane do walidacji. Im precyzyjniej opiszesz strukturę na początku, tym mniejsze ryzyko, że frontend zacznie wymuszać błędne skróty logiczne.
W headless commerce szczególnie ważne jest rozdzielenie danych statycznych i dynamicznych. Opisy, zdjęcia i treści mogą pochodzić z CMS lub PIM, natomiast ceny, dostępność i ograniczenia kompatybilności powinny być zarządzane przez backend lub warstwę logiki biznesowej. Taki podział upraszcza utrzymanie i rozwój.
- produkt bazowy i warianty
- reguły kompatybilności
- źródła cen i dostępności
- pola wymagane dla walidacji
- możliwość rozszerzania o nowe kategorie
Jak połączyć frontend z API bez utraty wydajności
Frontend konfiguratora powinien być lekki, responsywny i odporny na zmiany danych. Najlepiej, jeśli pobiera tylko informacje potrzebne w danym kroku konfiguracji, zamiast ładować wszystkie reguły naraz. Taki sposób projektowania ogranicza czas odpowiedzi i ułatwia obsługę mobilnych użytkowników.
API warto projektować wokół konkretnych działań użytkownika: pobrania opcji, sprawdzenia zgodności, przeliczenia ceny i zapisania konfiguracji. Przy większej złożoności dobrze sprawdza się warstwa pośrednia, która agreguje dane z kilku źródeł i zwraca frontendowi gotowy, uporządkowany wynik.
- pobieranie danych etapami
- agregacja danych w warstwie backendowej
- cache dla powtarzalnych zapytań
- walidacja po stronie serwera
- jasne komunikaty błędów dla użytkownika
Logika konfiguracji i walidacja po stronie backendu
Jednym z najczęstszych błędów jest przeniesienie zbyt dużej odpowiedzialności do frontendu. Interfejs może pomagać użytkownikowi, ale to backend powinien ostatecznie decydować, czy wybrane elementy mogą współistnieć. Dzięki temu konfiguracja pozostaje spójna niezależnie od urządzenia i sposobu interakcji.
Reguły konfiguracji mogą obejmować zależności między komponentami, ograniczenia techniczne, progi dostępności, minimalne i maksymalne zestawy opcji oraz zależności cenowe. W modelu headless warto trzymać je w miejscu, które da się testować, wersjonować i rozwijać bez przebudowy całego interfejsu.
- backend jako źródło prawdy
- wielopoziomowe reguły zależności
- wersjonowanie logiki konfiguracji
- testy regresji dla scenariuszy sprzedażowych
- możliwość zarządzania zmianami w ofercie
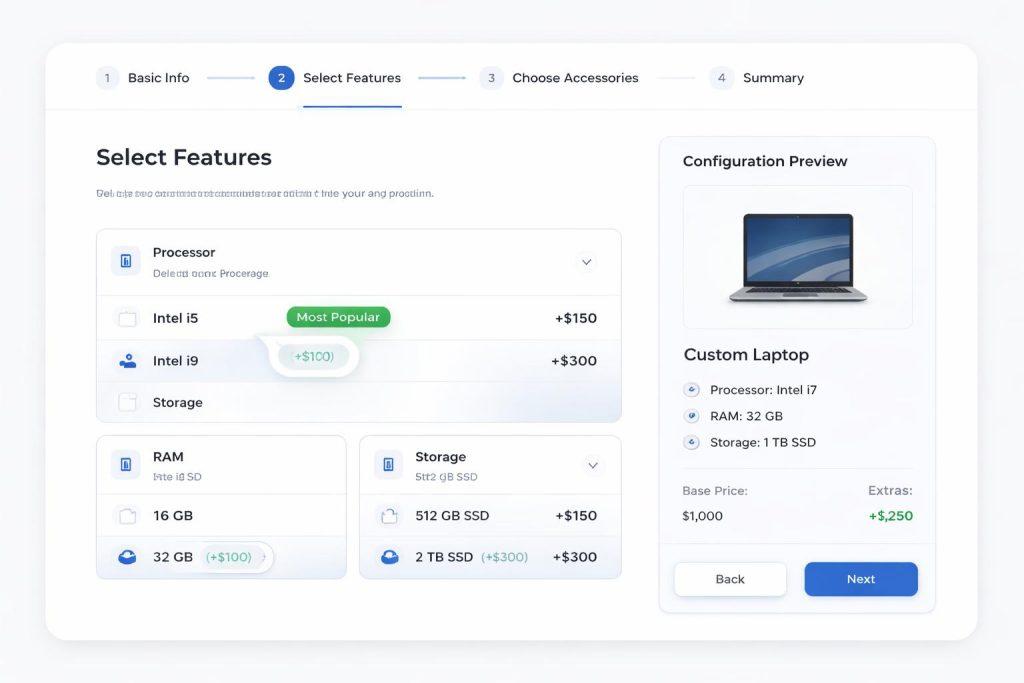
Jak zaplanować UX konfiguratora w środowisku headless
W headless commerce łatwo skupić się na technologii i pominąć doświadczenie użytkownika. Tymczasem konfigurator musi prowadzić klienta krok po kroku i nie może wymagać od niego znajomości technicznych szczegółów produktu. Dobrze zaprojektowany UX upraszcza wybór, pokazuje konsekwencje decyzji i ogranicza liczbę momentów niepewności.
Warto dopasować układ do realnego procesu decyzyjnego. Czasem lepiej działa kreator wieloetapowy, a czasem interfejs z podglądem na żywo i szybkim filtrowaniem. Nie ma jednego wzorca, ale zawsze potrzebna jest jasna hierarchia informacji i widoczny efekt każdego wyboru.
- prowadzenie użytkownika krok po kroku
- podgląd efektu wyboru w czasie rzeczywistym
- widoczna cena lub zakres ceny
- minimalizacja zbędnych kliknięć
- dopasowanie interfejsu do poziomu wiedzy klienta
Integracje z ERP, PIM, magazynem i innymi systemami
Jednym z najmocniejszych argumentów za headless commerce jest łatwiejsza integracja z zewnętrznymi systemami. Konfigurator może pobierać informacje o produktach z PIM, dostępność z magazynu, ceny z systemu sprzedażowego, a dodatkowe reguły biznesowe z dedykowanego backendu.
Takie rozwiązanie ogranicza ręczną aktualizację oferty i zmniejsza ryzyko niespójności, ale wymaga dobrego podejścia do synchronizacji. Jeśli dane zmieniają się w różnych systemach w różnym tempie, konfigurator musi wiedzieć, która informacja ma priorytet i jak długo można korzystać z cache.
- PIM jako źródło treści i parametrów
- ERP lub system sprzedaży dla cen i statusów
- magazyn dla dostępności
- warstwa integracyjna jako bufor i agregator
- priorytety danych i synchronizacja
Plan wdrożenia krok po kroku
Wdrożenie konfiguratora w headless commerce najlepiej prowadzić etapami, bo projekt łączy decyzje biznesowe, UX i development. Najpierw trzeba potwierdzić, czy produkt rzeczywiście wymaga konfiguracji, a następnie zmapować reguły, dane i punkty integracji. Dopiero później ma sens wybór stacku technologicznego i architektury API.
Kolejny krok to przygotowanie prototypu przepływu użytkownika oraz modelu danych. Prototyp pozwala sprawdzić, czy logika konfiguracji jest zrozumiała, a model danych pokazuje, czy da się ją stabilnie utrzymać. Potem można przejść do implementacji frontendu, backendu, cache, walidacji i testów na realnych scenariuszach.
Po uruchomieniu prace się nie kończą. Potrzebny jest monitoring błędów, analiza zachowań użytkowników i plan dalszych iteracji. Konfigurator rozwija się razem z ofertą, więc powinien mieć miejsce na kolejne reguły, produkty i automatyzację integracji.
- analiza potrzeb i złożoności produktu
- model danych i reguł
- prototyp UX
- integracja API i backend
- testy, monitoring i rozwój
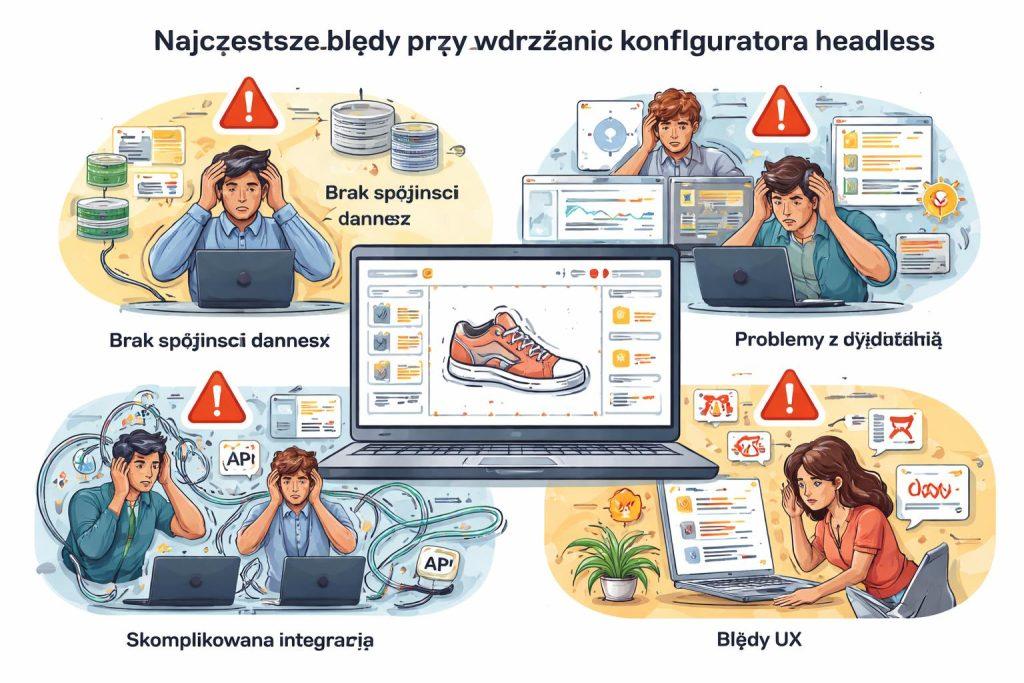
Najczęstsze błędy przy wdrażaniu konfiguratora headless
Największym błędem jest traktowanie headless jako celu samego w sobie. Jeśli architektura nie rozwiązuje konkretnego problemu biznesowego, może jedynie podnieść koszty projektu. Drugim częstym problemem jest przeniesienie całej logiki do frontendu, przez co konfigurator staje się trudny w utrzymaniu i podatny na niespójności.
Błędem jest też zbyt późne projektowanie modelu danych. Jeśli struktura produktów i reguł nie jest dobrze opisana przed implementacją, zespół zaczyna naprawiać problemy w kodzie zamiast budować rozwiązanie. Podobnie groźne są zbyt rozbudowane integracje bez warstwy pośredniej oraz brak planu cache i obsługi błędów.
Na końcu często pojawia się jeszcze jeden problem: brak procesu utrzymaniowego. Konfigurator, który nie ma właściciela biznesowego, monitoringu i ścieżki aktualizacji reguł, po kilku miesiącach zaczyna hamować sprzedaż zamiast ją wspierać.
- headless bez uzasadnienia biznesowego
- logika biznesowa w frontendzie
- brak dobrze opisanego modelu danych
- brak warstwy integracyjnej i cache
- brak procesu utrzymania po wdrożeniu
Jak połączyć konfigurator z wyceną i danymi z API
W praktyce sam konfigurator często nie wystarcza. Użytkownik oczekuje, że od razu zobaczy wpływ wyborów na cenę, dostępność lub termin realizacji. Dlatego warto projektować konfigurator razem z logiką wyceny i mechanizmem pobierania danych z API, a nie jako dwa osobne moduły.
Dobrze działa model, w którym każda istotna zmiana opcji uruchamia tylko niezbędne wywołania do backendu. Pozwala to zachować aktualność danych bez przeciążania systemu. Jeśli wycena jest dynamiczna, backend powinien zwracać nie tylko wartość końcową, ale też informacje pomocnicze, np. o dopłatach, ograniczeniach i czasie realizacji.
- wycena powiązana z aktualnym stanem konfiguracji
- zwracanie ceny bazowej i dopłat
- uwzględnianie dostępności i czasu realizacji
- minimalizacja zbędnych requestów
- spójna prezentacja danych w UI
Jak utrzymać konfigurator po wdrożeniu
Konfigurator to nie projekt jednorazowy, tylko element sprzedaży, który będzie się zmieniał wraz z ofertą. Dlatego już na etapie wdrożenia trzeba ustalić, kto odpowiada za reguły, treści, integracje i monitoring. Bez tego nawet dobrze zrobione rozwiązanie szybko zaczyna się rozjeżdżać z realną ofertą.
W praktyce warto ustalić cykl przeglądu reguł, obserwować błędy techniczne i analizować miejsca, w których użytkownicy najczęściej rezygnują z konfiguracji. Takie dane pomagają poprawiać zarówno UX, jak i logikę biznesową. Dobrze utrzymywany konfigurator powinien ewoluować razem z katalogiem produktów, a nie działać obok niego.
- właściciel biznesowy konfiguratora
- cykliczny przegląd reguł i danych
- monitoring błędów technicznych
- analiza porzuceń konfiguracji
- plan rozwoju nowych funkcji i integracji
Checklist
- Sprawdź, czy produkt faktycznie wymaga wieloetapowej konfiguracji lub złożonych reguł zależności.
- Zmapuj wszystkie warianty, opcje, ograniczenia i źródła danych.
- Określ, które dane mają pochodzić z PIM, ERP, magazynu i backendu.
- Zaprojektuj model danych tak, aby dało się go rozszerzać o kolejne kategorie produktów.
- Ustal, które reguły muszą być walidowane po stronie backendu.
- Zdefiniuj zakres odpowiedzialności frontendu, API i warstwy integracyjnej.
- Zaplanuj cache, obsługę błędów i fallback dla chwilowych problemów z API.
- Zaprojektuj UX krok po kroku z jasnym postępem i podglądem zmian.
- Przetestuj scenariusze brzegowe, konflikty między opcjami i aktualizacje danych.
- Ustal monitoring błędów, analitykę i proces utrzymania po wdrożeniu.
FAQ
Kiedy konfigurator produktów w modelu headless commerce ma największy sens?
Największy sens ma przy produktach z wieloma wariantami, zależnościami między opcjami, dynamiczną ceną i koniecznością integracji z innymi systemami. Headless sprawdza się też wtedy, gdy konfigurator ma działać na kilku kanałach i frontend musi rozwijać się niezależnie od silnika sklepu.
Czy każdy konfigurator produktów powinien być headless?
Nie. Jeśli produkt ma proste warianty i niewielką liczbę reguł, prostsza architektura może być tańsza i szybsza we wdrożeniu. Headless warto wybierać wtedy, gdy złożoność biznesowa realnie uzasadnia większą elastyczność techniczną.
Gdzie powinna znajdować się logika konfiguracji: na froncie czy w backendzie?
Najważniejsze reguły, walidacja, kompatybilność komponentów, ceny i dostępność powinny być po stronie backendu. Frontend ma wspierać użytkownika, ale nie powinien być jedynym miejscem przechowywania logiki biznesowej.
Jakie systemy najczęściej integruje się z konfiguratorami headless?
Najczęściej są to PIM, ERP, system magazynowy, system sprzedażowy, CMS oraz dedykowane usługi API. W większych projektach dochodzi też warstwa integracyjna, która agreguje dane i porządkuje odpowiedzi dla frontendu.
Jak uniknąć problemów z wydajnością przy konfiguratorze headless?
Warto pobierać dane etapami, stosować cache dla powtarzalnych zapytań, ograniczać liczbę wywołań na żywo i projektować API wokół konkretnych działań użytkownika. Dobrze działa też warstwa pośrednia, która redukuje liczbę bezpośrednich połączeń z wieloma systemami.
Podsumowanie
Headless commerce jest dobrym wyborem dla konfiguratorów produktów, które muszą obsługiwać złożone reguły, dynamiczne dane i wiele integracji. Najlepszy efekt daje rozdzielenie prezentacji od logiki biznesowej, z backendem jako źródłem prawdy i frontendem skupionym na UX. Kluczowe są dobrze zaprojektowany model danych, warstwa integracyjna, cache, testy scenariuszy oraz utrzymanie po wdrożeniu.


