Praktyczny przewodnik po projektowaniu mapowania danych między API a WordPressem: model danych, źródła prawdy, reguły synchronizacji, walidacja, obsługa błędów i panel administracyjny, który realnie ogranicza ręczne aktualizacje treści.
Najlepiej zacząć od wspólnego modelu danych, ustalić jedno źródło prawdy dla każdego pola, zaprojektować reguły transformacji i synchronizacji, a potem dodać walidację, logi, obsługę wyjątków oraz panel administracyjny. To właśnie architektura mapowania, a nie samo pobieranie danych, decyduje o tym, czy ręczne aktualizacje faktycznie znikną.
Najważniejsze wnioski
- Najpierw projektuje się model danych, dopiero później integrację.
- Każde pole powinno mieć jedno nadrzędne źródło prawdy.
- Nie wszystkie dane muszą synchronizować się w czasie rzeczywistym.
- Walidacja, logowanie i retry są krytyczne dla stabilności integracji.
- W WordPressie warto oddzielić pola automatyczne od redakcyjnych.
- Panel administracyjny powinien pokazywać status, wyjątki i konflikty.
- Dobre mapowanie ogranicza ręczne aktualizacje, ale ich nie eliminuje całkowicie.
- Dlaczego samo podłączenie API do WordPressa nie wystarcza
- Jak zbudować wspólny model danych przed wdrożeniem integracji
- Jak ustalić źródło prawdy dla każdego pola
- Jak odwzorować pola z API do WordPressa bez utraty spójności
- Które dane synchronizować w czasie rzeczywistym, a które cyklicznie
- Jak zabezpieczyć integrację przed błędami, duplikatami i niepełnymi danymi
- Jak zaprojektować panel administracyjny dla redakcji i sprzedaży
- Jak wdrożyć proces utrzymania i rozwijania mapowania danych
- Przykładowy schemat projektowy dla WordPressa
Dlaczego samo podłączenie API do WordPressa nie wystarcza
W wielu projektach integracja kończy się na pobraniu danych z API i zapisaniu ich w WordPressie. To jednak dopiero pierwszy etap. Jeśli nie zaprojektujesz modelu danych, zasad nadpisywania i odpowiedzialności za pola, bardzo szybko pojawią się niespójności, duplikaty i ręczne poprawki, które miały zostać wyeliminowane.
Dobrze zaprojektowane mapowanie działa jak warstwa tłumacząca między systemami. WordPress nie musi znać wewnętrznej logiki zewnętrznego API, a redakcja pracuje na polach, które mają sens biznesowy. To szczególnie ważne wtedy, gdy CMS obsługuje jednocześnie wiele typów treści, produktów lub integracji.
Integracja bez mapowania zwykle prowadzi do chaosu w treściach. CMS powinien mieć własny, logiczny model danych. WordPress musi wiedzieć, które pola są automatyczne, a które redakcyjne.
- Integracja techniczna to nie to samo co gotowy proces biznesowy.
- Bez zasad odpowiedzialności za dane szybko pojawiają się konflikty.
- CMS powinien odwzorowywać logikę użycia danych, a nie tylko strukturę API.
Jak zbudować wspólny model danych przed wdrożeniem integracji
Najważniejszym krokiem jest opisanie modelu danych niezależnie od technologii. Trzeba spisać encje, pola, relacje i wyjątki: co jest rekordem, co wariantem, co metadanymi, a co treścią redakcyjną. Dopiero na tej podstawie warto projektować odwzorowanie do WordPressa.
Dobry model powinien uwzględniać nie tylko obecne potrzeby, ale też rozwój systemu. Jeśli na starcie przewidzisz rozszerzenia, statusy, wersjonowanie lub dodatkowe źródła danych, unikniesz przebudowy integracji po kilku miesiącach.
Warto też rozdzielić dane operacyjne od treści prezentacyjnych. Inaczej projektuje się synchronizację ceny, stanu magazynowego czy dostępności, a inaczej opisów, nagłówków, sekcji FAQ i elementów marketingowych.
- Opisz encje i relacje: rekord, wariant, atrybut, status, źródło.
- Rozdziel dane dynamiczne od statycznych.
- Uwzględnij przyszłe rozszerzenia modelu.
- Przygotuj słownik pojęć dla biznesu, redakcji i developmentu.
Jak ustalić źródło prawdy dla każdego pola
Jedna z najczęstszych przyczyn problemów integracyjnych pojawia się wtedy, gdy kilka systemów może edytować to samo pole. W efekcie powstają konflikty: który opis jest aktualny, która cena ma pierwszeństwo, skąd pochodzi status publikacji. Bez jasnych zasad ręczne poprawki stają się nieuniknione.
Dlatego dla każdego pola trzeba ustalić jedno źródło prawdy. Ceny mogą pochodzić z ERP, dostępność z systemu magazynowego, a treści eksperckie z WordPressa. Jeśli pole może zmieniać się z kilku miejsc, warto zdefiniować hierarchię: system nadrzędny, override ręczny i warunki wygaszenia nadpisania.
Taki model ułatwia też pracę zespołom nietechnicznym. Redakcja wie, co może edytować, dział sprzedaży rozumie granice odpowiedzialności, a developer nie musi każdorazowo rozwiązywać konfliktu danych od zera.
- Jedno pole powinno mieć jedno nadrzędne źródło.
- Jeśli są wyjątki, zapisz je w regułach biznesowych.
- Dodaj mechanizm ręcznego nadpisania tam, gdzie jest to potrzebne.
- Określ, kiedy nadpisanie wygasa i kto je zatwierdza.
Jak odwzorować pola z API do WordPressa bez utraty spójności
Mapowanie nie powinno polegać na prostym kopiowaniu nazw pól. Trzeba dopasować strukturę danych do sposobu, w jaki WordPress faktycznie zarządza treścią. Czasem jedno pole z API trzeba rozbić na kilka pól w CMS, a czasem kilka pól źródłowych połączyć w jedną sekcję treści.
Ważne jest także dopasowanie typów danych. Inaczej obsługuje się tekst, liczby, tablice, daty, statusy czy obiekty zagnieżdżone. Jeśli przewidzisz transformacje, normalizację i walidację już na etapie projektowania, później unikniesz ręcznych poprawek wynikających z błędnych formatów.
Przydaje się dokument mapowania: lista pól źródłowych, pól docelowych, reguł transformacji, walidacji, statusu synchronizacji i systemu odpowiedzialnego za dane. Taki dokument staje się wspólnym językiem dla biznesu, redakcji i developerów.
- Mapuj znaczenie pola, nie tylko jego nazwę.
- Zapisz transformacje i normalizację danych.
- Dokumentuj zależności między polami zewnętrznymi i polami CMS.
- Uwzględnij typy danych i wartości opcjonalne.
Które dane synchronizować w czasie rzeczywistym, a które cyklicznie
Nie każda informacja wymaga natychmiastowej aktualizacji. W wielu projektach lepiej działa model hybrydowy: część danych pobierana jest po zdarzeniu, część cyklicznie, a część ręcznie zatwierdzana przez redakcję. To ogranicza obciążenie systemów i zmniejsza ryzyko błędów.
Aktualizacje w czasie rzeczywistym mają sens tam, gdzie liczy się szybkość reakcji: statusy, dostępność, krytyczne zmiany operacyjne. Z kolei treści rozbudowane, opisy, atrybuty pomocnicze czy elementy marketingowe często mogą być odświeżane rzadziej, o ile mają jasno ustaloną rolę w procesie publikacji.
Dobrym podejściem jest podział pól na trzy grupy: automatyczne, półautomatyczne i ręczne. Dzięki temu od razu widać, gdzie integracja daje największą wartość, a gdzie człowiek powinien pozostać w pętli decyzyjnej.
- Realtime tylko tam, gdzie naprawdę jest potrzebny.
- Synchronizacja cykliczna często jest stabilniejsza i tańsza.
- Podział na tryby aktualizacji ułatwia utrzymanie CMS.
- Webhooki i cron mogą działać równolegle, jeśli są dobrze rozdzielone.

Jak zabezpieczyć integrację przed błędami, duplikatami i niepełnymi danymi
Nawet dobrze zaprojektowane mapowanie nie zadziała bez warstwy bezpieczeństwa. Trzeba założyć, że API czasem zwróci brakujące dane, niepoprawny format albo wartość, której WordPress nie powinien przyjąć. Jeśli to zignorujesz, błędy szybko przeniosą się na front strony.
Podstawą jest walidacja po stronie integracji: sprawdzenie wymaganych pól, typów, formatów i relacji między danymi. Równie ważne są mechanizmy antyduplikacyjne, które zapobiegają tworzeniu wielu rekordów dla tego samego obiektu. Najlepiej oprzeć je o techniczny identyfikator zapisany po obu stronach.
Warto też mieć logi synchronizacji i prosty sposób ponowienia błędnych operacji. Dzięki temu zamiast ręcznie poprawiać setki rekordów, możesz szybko odtworzyć tylko te, które rzeczywiście się nie udały.
- Waliduj dane przed zapisem do CMS.
- Stosuj techniczne identyfikatory rekordów.
- Loguj błędy i umożliwiaj ponowne przetworzenie rekordów.
- Zabezpiecz się przed częściowym zapisem danych.
- Projektuj integrację tak, aby dało się ją bezpiecznie powtórzyć.
Jak zaprojektować panel administracyjny dla redakcji i sprzedaży
Jeżeli chcesz naprawdę ograniczyć ręczne aktualizacje, panel administracyjny musi być prosty, czytelny i zorientowany na zadania użytkowników biznesowych. Samo wystawienie danych z API nie wystarczy, jeśli redakcja nie będzie wiedziała, co można edytować, a co jest zarządzane automatycznie.
Panel powinien pokazywać status integracji, ostatnią synchronizację, konflikty, wyjątki i pola dostępne do ręcznej korekty. Dobrą praktyką jest też rozdzielenie widoku dla administratora, redaktora i działu sprzedaży, aby każdy widział tylko te akcje, które są dla niego istotne.
Warto przewidzieć mechanizmy takie jak ręczne odświeżenie rekordu, podgląd różnic między źródłem a CMS, blokada nadpisania wybranych pól oraz oznaczanie rekordów wymagających akceptacji. Taki panel znacząco zmniejsza liczbę zgłoszeń do działu technicznego.
- Pokaż statusy integracji i wyjątki.
- Rozdziel uprawnienia według roli użytkownika.
- Dodaj podgląd różnic i ręczne odświeżanie rekordów.
- Wydziel pola tylko do odczytu i pola edytowalne.
- Pokaż, co nadpisało ostatnią wartość.
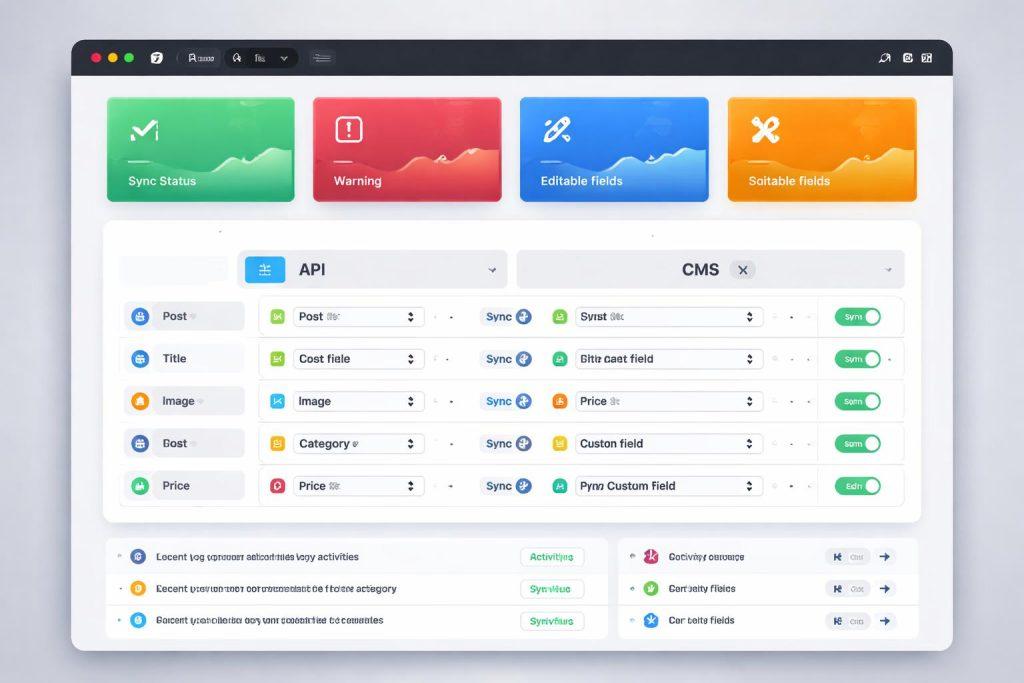
Jak wdrożyć proces utrzymania i rozwijania mapowania danych
Mapowanie danych nie kończy się w dniu wdrożenia. W praktyce model danych, formaty API i potrzeby biznesowe zmieniają się regularnie, więc warto od razu przewidzieć proces utrzymania. Najlepiej traktować mapowanie jak żywy dokument i część architektury, a nie jednorazowy opis.
Dobry proces obejmuje wersjonowanie zmian, testy integracji po modyfikacjach, przegląd logów oraz okresową weryfikację, czy pola nadal są używane zgodnie z założeniami. To szczególnie ważne, gdy projekt obsługuje wiele systemów zewnętrznych albo różne zespoły edytują treści w tym samym WordPressie.
Jeżeli integracja ma ograniczać ręczne aktualizacje na dłuższą metę, musi być przewidywalna i łatwa w rozwoju. Dlatego już na starcie warto zdefiniować odpowiedzialności, procedurę zmian i sposób dokumentowania nowych pól oraz reguł synchronizacji.
- Traktuj mapowanie jako element utrzymania, nie tylko wdrożenia.
- Wersjonuj zmiany i testuj wpływ na integrację.
- Aktualizuj dokumentację wraz z rozwojem systemu.
- Zaplanuj przegląd mapowania po każdej większej zmianie w API lub CMS.
Przykładowy schemat projektowy dla WordPressa
W praktyce warto oprzeć projekt o stały zestaw kroków. Najpierw opisz źródła danych, potem zmapuj pola, następnie rozdziel odpowiedzialność między systemy, a na końcu dodaj warstwę kontroli i monitoringu. Taka kolejność pozwala uniknąć sytuacji, w której technicznie działająca integracja nie nadaje się do realnej pracy operacyjnej.
Dobrze zaprojektowany schemat dla WordPressa zwykle obejmuje: import danych zewnętrznych, zapis identyfikatorów technicznych, walidację, logowanie, panel wyjątków, ręczne nadpisania oraz cykliczny przegląd jakości danych. To właśnie te elementy decydują o tym, czy automatyzacja faktycznie odciąża zespół.
Jeśli projekt dotyczy sklepu, konfiguratora lub bardziej złożonej strony firmowej, taki schemat warto rozwinąć o role użytkowników, workflow akceptacji i zasady publikacji. Im bardziej złożone źródła danych, tym ważniejsza jest spójna architektura mapowania.
- Opis źródeł danych i ich właścicieli.
- Dokument mapowania pól i transformacji.
- Techniczne identyfikatory rekordów.
- Walidacja i mechanizmy retry.
- Panel wyjątków i ręczne nadpisania.
- Monitoring oraz okresowa kontrola jakości.
Checklist
- Zidentyfikuj wszystkie źródła danych i właścicieli poszczególnych pól.
- Opisz docelowy model danych w WordPressie przed wdrożeniem integracji.
- Przypisz każdemu polu jedno źródło prawdy.
- Oznacz pola edytowalne ręcznie i pola zarządzane automatycznie.
- Ustal reguły konfliktów i priorytety nadpisywania danych.
- Zaprojektuj walidację typów, pustych wartości i niezgodnych formatów.
- Dodaj logowanie błędów oraz historię synchronizacji.
- Przygotuj mechanizm ręcznego odświeżania pojedynczych rekordów.
- Zaplanuj obsługę przerw w dostępności API i timeoutów.
- Stwórz prosty panel administracyjny do kontroli wyjątków i statusów integracji.
- Wersjonuj mapowanie i dokumentuj zmiany w modelu danych.
- Przetestuj integrację na danych brzegowych przed uruchomieniem produkcyjnym.
FAQ
Czy każde pole w WordPressie powinno być synchronizowane z API automatycznie?
Nie. Najlepiej podzielić pola na automatyczne, półautomatyczne i ręczne. Automatycznie synchronizuj to, co jest operacyjne i często się zmienia, a pola redakcyjne zostaw w CMS, jeśli mają wartość marketingową lub wymagają kontroli człowieka.
Co jest ważniejsze: samo pobranie danych z API czy projekt mapowania?
Projekt mapowania. Samo pobranie danych to dopiero techniczny transport. Dopiero model danych, źródła prawdy, reguły transformacji i obsługa wyjątków decydują o tym, czy integracja będzie stabilna i praktyczna w codziennej pracy.
Jak ograniczyć konflikty między redakcją a automatyczną synchronizacją?
Trzeba jasno oznaczyć, które pola są tylko do odczytu, które można nadpisać ręcznie, a które zawsze mają pierwszeństwo z zewnętrznego systemu. Pomaga też historia zmian, status synchronizacji i mechanizm ręcznego override z datą wygaśnięcia.
Czy webhooki są lepsze niż synchronizacja cykliczna?
To zależy od typu danych. Webhooki sprawdzają się przy zdarzeniach krytycznych i szybkich zmianach, a synchronizacja cykliczna bywa stabilniejsza dla większych zbiorów danych i mniej wrażliwa na chwilowe problemy po stronie API. W praktyce często najlepiej działa model hybrydowy.
Jak zabezpieczyć WordPress przed błędnymi danymi z API?
Przed zapisem należy sprawdzić wymagane pola, formaty, typy danych i zależności między nimi. Warto też zapisywać techniczne identyfikatory rekordów, logować błędy, obsługiwać częściowe niepowodzenia i umożliwiać ponowne przetworzenie tylko tych rekordów, które faktycznie się nie udały.
Podsumowanie
Dobre mapowanie danych między API a CMS w WordPressie nie polega na prostym przepisaniu pól z jednego systemu do drugiego. Kluczowe jest zaprojektowanie wspólnego modelu danych, ustalenie źródeł prawdy, zdefiniowanie reguł synchronizacji i transformacji oraz dodanie warstwy walidacji, logów i obsługi wyjątków. Jeśli do tego dołączysz przejrzysty panel administracyjny, WordPress zacznie realnie odciążać redakcję i dział sprzedaży zamiast generować kolejne ręczne poprawki.


